

Exploratory Newsletter Vol. 96
Exploratory Newsletter Vol. 96

世の中には全く何も学ばない人達がいる、それは彼らが自分が理解できたと思うのが早すぎるからだ。
アレキサンダー・ポープ、詩人、イギリス、1688 - 1744
こんにちは、西田です!
2週間前にデータサイエンス・ブートキャンプ・トレーニングとデータサイエンス勉強会のために日本を訪れていましたが、今回も多くのExploratoryユーザーの方たちと直接お会いすることができ、非常にエキサイティングな時間を過ごすことができました。
今回の来日では以前と比べてマスクをしている人たちもだいぶ減り、アメリカのようにいよいよコロナ前、もしくは平常に戻ったかのようで、街を歩く人たちの顔にも笑顔が戻ってきたかのような印象を受けました。
ブートキャンプや勉強会、さらにお客様訪問にしても、やはり同じ部屋の中で直接お会いし、会話を交わすことができるのはいいですね。もちろんコミュニケーションもより円滑となり、お互いの理解も進みますが、それ以上に人とのつながりによってしか得られない刺激や興奮を感じることができます。
次回の日本訪問は9月となりますが、その際にはまた多くの人たちと直接お会いできるのを楽しみにしております。
ところで前述のデータサイエンス勉強会の方ですが、録画の方をこちらに公開しておりますので、参加できなかったが興味があるという方はぜひご参照ください。
それでは、久々のニュースレターとなりますが、今回は4件ほどのデータ関連記事を共有したいと思います。
最近の興味深いデータ関連記事
ハーバード・ビジネススクールの教授がExcelを使ってデータを不正加工し、調査結果を捏造していた話
Data Falsificada (Part 1): "Clusterfake"- リンク
2021年の秋、行動経済学の分野で有名なダン・アリエリー教授が率いるチームで研究を行っていた、ハーバード・ビジネススクールのFrancesca Gino教授が自分たちの主張にとって都合のいい結果を得るためにデータを不正加工していたことが追及されました。結果として彼女は休職となり、彼女たちが発表した4つの論文は撤回されました。
「正直さ」についての研究で、実験の質問に答える前に「嘘をついていない」ということに署名した人たちは、答えた後に署名した人たちに比べて、より正直に答えていたというものでした。
ところが、一部の実験参加者の人たちのデータが改竄され、そのことによって結果が大きく変わってしまいました。「正直さ」についての研究を行っていた人たちが「正直さ」を諦めてしまっていたというのが皮肉です。
不正を追及したチームはこの研究結果を見て何かがおかしいと思い、その研究の元となるエクセルのデータを入手したところ、回答者のIDでソートされているはずのデータの中に、不自然にソートされていない行があるのが発見されました。先に署名したグループと後で署名したグループ、さらに署名してないグループという3つのグループがあったのですが、順番がおかしくなっている回答者は実際とは違ったグループに割り当てられていることが判明しました。
このデータ改竄に関しての決定打となったのは、エクセルのcalcChain.xmlというファイルでした。実はエクセルはこのファイルにセルの計算順序を記録していて、エクセルファイルを解凍するとこのファイルにアクセスできます。
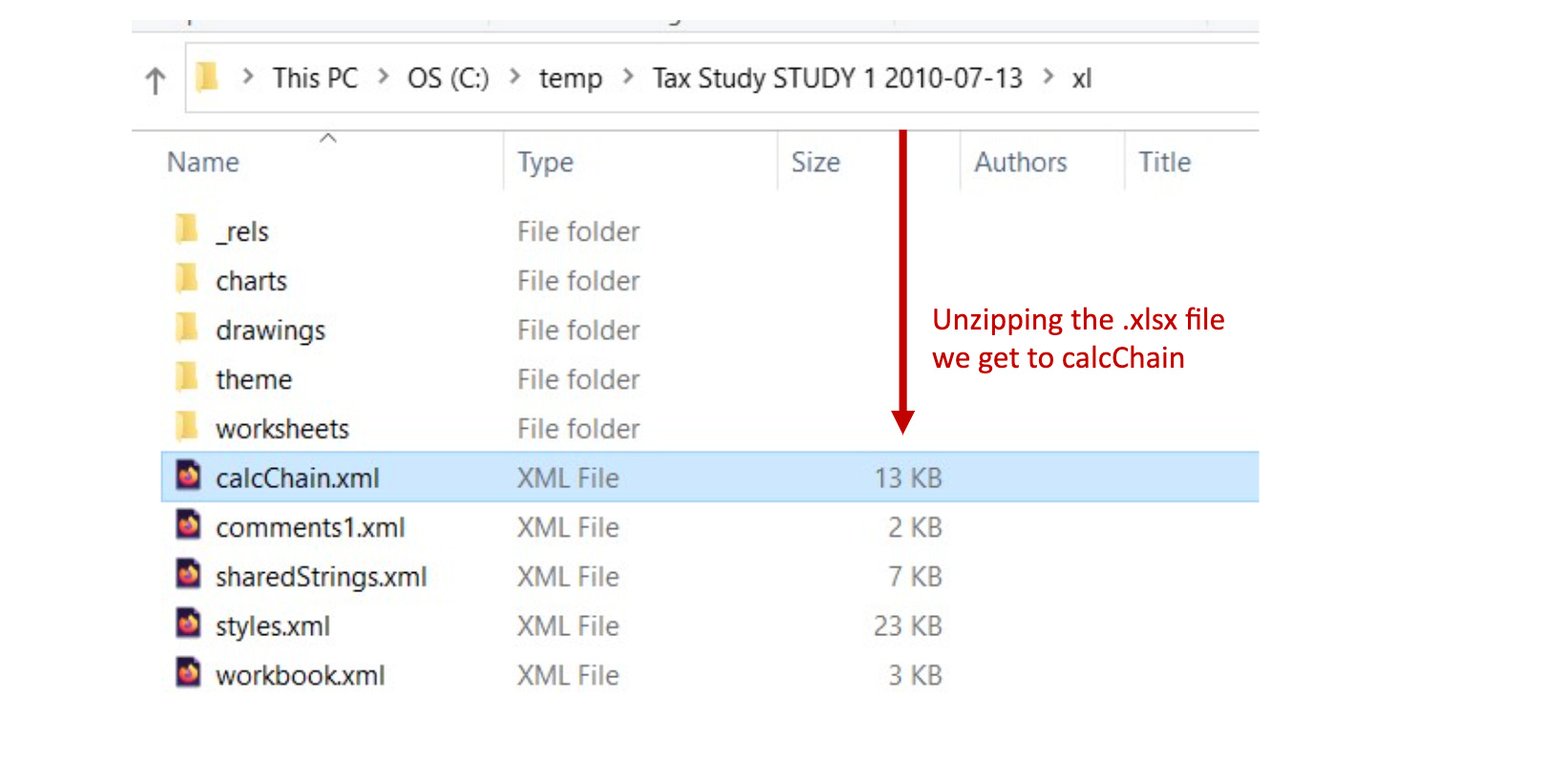
そこに記録されていた計算順序により、不自然なソートが加えられる前のデータの位置を確認することができ、一部のデータのグループの割当がエクセルの中で変更されていたことを確信できたとのことです。

今でもエクセルのようなデータの再現性が見えないツールを使ってこうした研究のデータ分析が行われているというのは残念なことです。確かにエクセルを使えば簡単にデータを改竄することができます。しかし、そうした改竄は今回のようにバレることもあり、その場合は自分のキャリアが台無しになってしまうだけでなく、業界全体の信用も失われてしまうことになります。
それでも研究者は予算やステータスなどを含め絶えず何らかの圧力の元にあるため、自分に都合のいい方向へデータを誘導したいというインセンティブを持っています。これを個人の倫理観に頼っている限りは、同じようなことはこれからも繰り返されるでしょう。
そこで、データの再現性を保証し、分析過程を透明化するするためにRやPythonなどプログラミング言語を使ったり、そうでなければExploratoryのような再現性を保証するUIツールを使ったりする研究者が増えてきているのですが、残念ながら経済学や経営学といったいわゆる「文系」のエリアではエクセルがまだまだ主流のようです。今回のような事件をきっかけに状況が変わっていくことを期待します。
アメリカ政府は市民に関するデータを買収中
The US Is Openly Stockpiling Dirt on All Its Citizens - リンク
最近機密解除されたアメリカの国家情報局のレポートにより、アメリカ政府が自国民の個人情報データを大量に買い付けている事実が明らかになりました。
アメリカでは個人情報を集めそれを売ることをビジネスにするデータブローカーという業者がいます。この事自体は特に真新しいことでもなく、すでに多くの人が知っていることですが、政府がそうしたデータを収集しているとなると問題になります。
こうした個人情報データには、個人がどこに行ったかを追跡できるモバイルデータも含まれています。この手のデータは匿名化されているのですが、実は他のデータとつなぎ合わせることで簡単に個人の身元を突き止めることができます。
アメリカでは政府や警察などが、ある特定の個人のモバイル(スマホ)の位置情報を取得したい場合、それは憲法で守られているプライベートな情報のため、裁判所の許可が必要となります。
しかし、前述のデータブローカーから買い付けた個人情報データを使うことで、政府は裁判所の許可を取ることなく、個人の位置情報を特定することができるようになります。例えば、政府にとって都合の悪い集会に誰が参加していたかどうかを政府は簡単に調べることができるようになるということです。
だからこそ、国民のプライバシーを守るために作られた法律によって、政府機関がプライベートなデータを取得するのは禁じられています。つまり法律上、政府は国民の情報を民間から取得できないとういことです。
しかし、こうしたデータは「誰でも」買うことができるデータなので、そういう意味では「パブリック」なデータであり、「プライベート」ではないため、政府が取得するのは問題ないというのが、アメリカ政府または情報機関の見解のようです。
企業による個人情報データの扱いがよく問題になりますが、私たちが本当に懸念すべきは、政府による個人情報(位置情報を含む)を使った個人の監視、つまりジョージ・オーウェルが1984で描いた世界がもうそこまで来ているという事実です。
ChatGPTの回答をそのまま使った弁護士が罰金を払う羽目に
Two US lawyers fined for submitting fake court citations from ChatGPT - リンク
最近、ニューヨークである航空会社を相手取った飛行機事故に関する法廷で、弁護士がChatGPTが作り上げた6件の架空の判例を事実だと信じ、そのまま取り上げてしまったために偽証罪となり、$5,000(約70万円)の罰金を払うことになったというニュースがありました。
いつもの検索方法だと過去の判例が見つからなかったため、ChatGPTを使ったところ、使える判例が出てきたとのことですが、それらは実際には起きていない事件に関するものや、現実には存在しない航空会社を相手にした訴訟でした。
ChatGPTによる「フェイクニュース」という点では、少し前になりますが、ありもしないワシントン・ポストの記事を元にセクハラを非難されるというとばっちりを受けたアメリカの法律分野の教授のニュースがありました。(リンク)
前にも書きましたが、ChatGPTは何かを調べるときには非常に便利なツールなのですが、いつも「正しい答え」を教えてくれるとは限りません。何が正しいかというのは、ChatGPTのモデルの元となっているデータに大きく影響されますし、セイフティー・レイヤーと言われる、人間の手による調整も入っています。(リンク)
今まで見つからなかったものがChatGPTのおかげで見つかったというのは、興奮しがちですが、「今まで見つからなかった」のは実際に存在しないからだったかもしれません。ChatGPTに限らず何であっても、あまり過信せず、適度な懐疑心を持ち、最低限のチェックをする必要があるということですね。
最新のChatGPTによる犠牲者 - Stack Overflow
Stack Overflow is ChatGPT Casualty: Traffic Down 14% in March - リンク
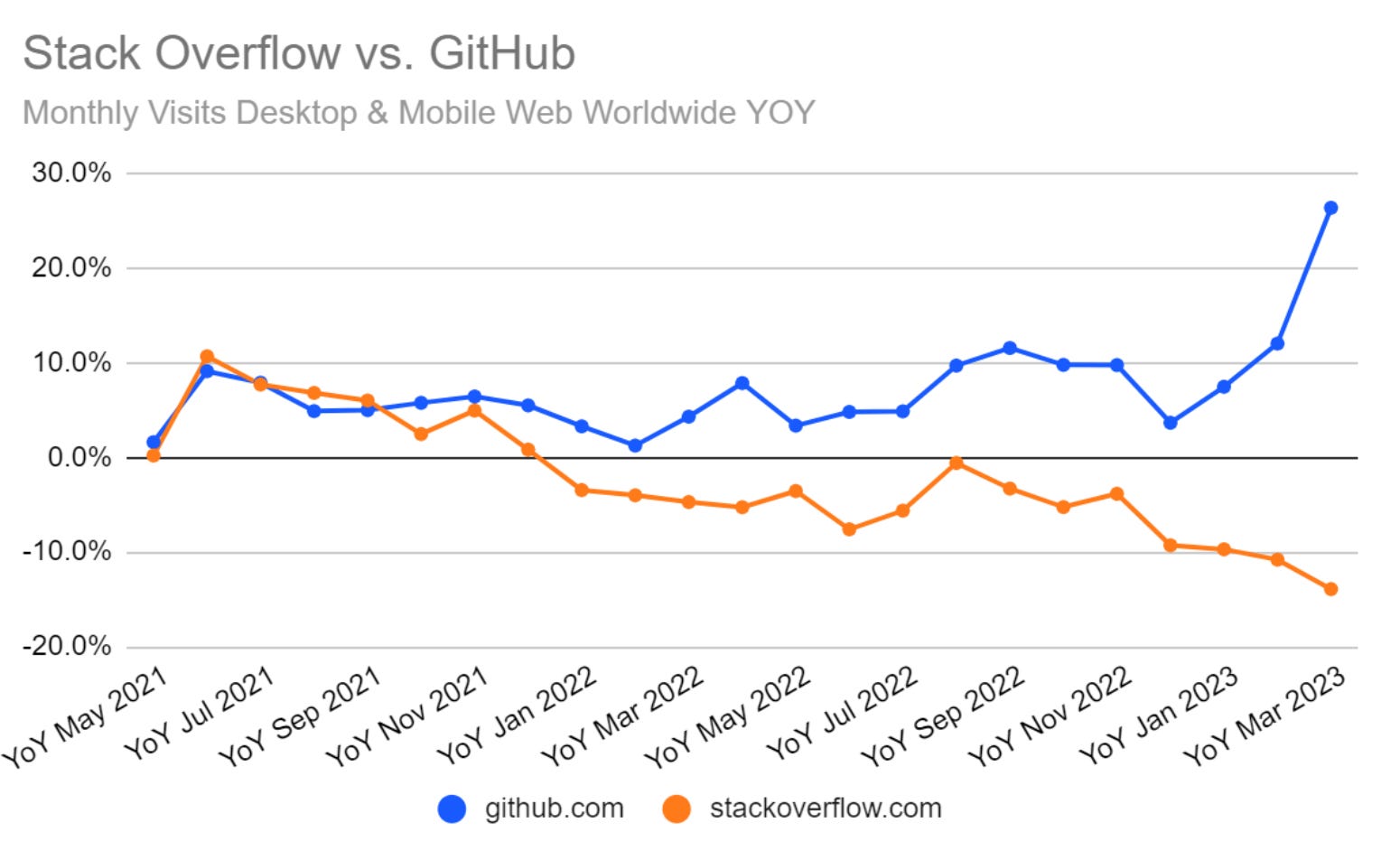
少し古い記事になりますが、プログラマーが困ったときに解決法を探しに行くStack Overflowというウェブサイトがありますが、最近そこへのトラフィックが下がりつつあり、直近では前年比で14%もダウンしているとのことでした。逆に、ソフトウェアを開発するときにコードを保管しておく場所であるGithubへのトラフィックは、同じ時期に26%ほど上昇しているとのことでした。
その理由は、GithubのCoPilotという機能のせいではないかと言われています。このCoPilotはプログラミングのコードを自然言語をもとに生成してくれたりするもので、Stack Overflowへのトラフィックが落ち始める前に、もとの自家製LLM(Large Language Model)からOpen AIのChatGPT-4に切り替えたとのことです。
以前であれば、困ったときにはStack Overflowに行って見つけたコードをコピペする、というのは多くのプログラマーにとって当たり前だったのですが、最近のLLMの進化は開発のあり方を大きく変えてしまいました。
ただ、2つほど気になる点があります。
そもそもChatGPTのようなLLMは膨大なデータをもとに作られているのですが、プログラミングに関してはStack Overflowからのデータがかなり貢献しているでしょう。そうであれば、これはビジネス慣行という点で倫理的にどうなのかと思います。
ただそれ以上に、ユーザー(この場合はプログラマー)にとって問題だと思うのは、Stack Overflowのような場所ではコミュニティの参加者による議論が活発に行われます。そして、サイトに来た人は、なぜこのコードが最適なのか、または他のコードのほうが良いかもしれないのか、といった議論の途中経過を見ることができます。それに対して、ChatGPTのようなモデルは「最適」だという答えをいきなり出してくるので、それがなぜ正しいのか、なぜ最適なのか判断しかねるのではないか、ということです。
ChatGPTに限らず、現在のいわゆるAIと言われるものには「価値基準」というものがありません。こればかりは人間が作り出すものです。そのため何が「最適」なのかという点に関しては注意が必要です。
今週のチャート

最近の研究開発予算における世界のトップ企業のチャートですが、アメリカのテック企業と欧米の製薬企業が上位を占めています。中国の企業も一部入っていますが、企業による研究開発予算という点では、まだまだアメリカに引けを取っています。
日本からはトヨタが辛うじて入っているだけなのが、寂しい気持ちになります。
データサイエンス・ブートキャンプ・トレーニング #32

次回の「データサイエンス・ブートキャンプ」は東京で9月に開催予定です!
今回もクラスルーム形式のみでの開催となります。
ビジネスのデータ分析だけでなく、日常生活やキャリア構築にも役立つデータリテラシー、そして「よりよい意思決定」をしていくために必要になるデータをもとにした科学的思考もいっしょに身につけていただけるトレーニングとなっています。
データサイエンス、統計の手法、データ分析を1から体系的に学ぶことで、ビジネスの現場で使える実践的なスキルを身につけたいという方は、ぜひこの機会に参加をご検討ください!
日時:
2023年9月26日(火), 27日(水), 28日(木)
以上となります。
それでは、素晴らしい週末をお送りください!
西田, Exploratory/CEO
KanAugust