


Exploratory Newsletter Vol. 94

”求めなさい。そうすれば、与えられる。探しなさい。そうすれば、見つかる。門をたたきなさい。そうすれば、開かれる。”
マタイによる福音書 7:7-8
こんにちは、西田です!
キリスト教徒でない私が聖書の一文を引用するのはおこがましいのですが、この言葉はデータ分析するにあたっても、さらに現在のような混沌とした世の中において何が真実であるのかを追求する上でも、非常に重要な教訓だと思います。
データがあれば何か知見が得られる、ニュースを読めば何かの真実がわかる、と思う人が多いのですが、実はそれではいつまで経っても真実に近づいていくことはできません。
真実に近づくためには、もしくは何が正しいのかを判断するためには、事前に何らかの仮説を持ち、それをもとに何を知ろうとしているのか、疑問に答えるためには何を知るべきなのか、何がわかればその仮説は間違っていることになるのか、といったことをはっきりさせた上で、データなり、ニュースなりに向き合うことが求められます。
受動的にデータやニュースといったシャワーを浴び、何かが分かるようになるのを期待するのではなく、能動的にデータやニュースに向き合うことで、知るべき答えを探し出すことができる。こうしたはるか昔から教えられる教訓を、今のようなデータサイエンス、インターネット、デジタルの時代にこそ、私達はもっと真剣に受け止める必要があるのではないかと思います。
手に入れることができる情報が増えれば増えるほど、真実からはどんどん離れていった、そうしことがないように心がけたいものです。
それでは、今週は3つほどのトピックをみなさんと共有させていただきます。
最近の興味深いデータ関連記事
最初の差を覆す線形回帰のちょっとした傾きの話
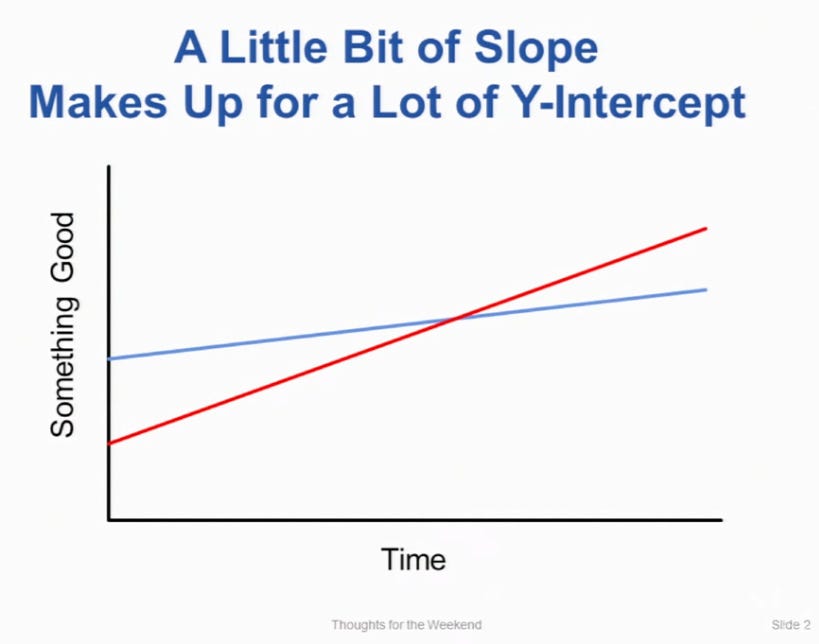
データサイエンスでは様々な予測モデルがありますが、それぞれの仕組みから人生や考え方などに関しての多くの示唆を得ることができます。
今回は、数多くある予測モデルの中でも最もシンプルで古くから使われている「線形回帰」が教えてくれる、新しい仕事を始めるとき、または仕事のキャリアを構築していくさいに重要な心がけに関する話です。
これはもともと、私がExploratoryという会社を創業する頃にある知人が紹介してくれた、スタンフォード大学の教授によるコンピューターサイエンスのクラスの生徒に向けた話(リンク)ですが、どんな仕事であっても一流を目指す人であれば誰にでも役に立つ話ではないかと思います。
Woke(ウォーク)なAIに対抗するAIの開発準備するイーロン・マスク
Fighting ‘Woke AI,’ Musk Recruits Team to Develop OpenAI Rival - リンク
アメリカではWoke(ウォーク)という言葉があります。元々は「目覚めた」人たちというような意味なのですが、最近はいわゆるリベラルメディアで「社会問題」とされている標語、スローガンに従い、逆にそれに従わない人たちを誹謗中傷しているだけの、行き過ぎたリベラルな人たちを総称してWokeと呼んだりします。
最近「ChatGPTは民主党のプロパガンダマシーンだった」という記事を書き、リベラルメディアや民主党が設定するアジェンダに沿った発言をするようにトレーニングされているこのAIは、何も知らない一般の人達に政治的に偏った情報をあたかも中立かのように提供してしまっていることに対して警鐘を鳴らしました。
もちろん、こうしたことに危惧するのは私だけではなく、リベラルな人が多いシリコンバレーでも極端に左傾化していない人たちの中にはこうした問題意識を持つ人たちがいます。
イーロン・マスク(テスラ、スペースX、Twitter、など)も同じように危惧していて、そうしたWokeなChatGPTに対抗するためのAIを作るために現在AIエンジニアをリクルート中とのことです。
ちなみに、イーロン・マスクは元々サム・アルトマンといっしょにChatGPT開発元のOpenAIを立ち上げたのですが、途中で意見が合わなくなりOpenAIを去っています。
ところでTwitter上では過去に、OpenAIのCEOであるサム・アルトマンがChatGPTが「Wokeになるよう」にトレーニングするのは問題ないと認めるような発言をしていました。それに対してイーロン・マスクは、こうしたChatGPTのような「AI」がWokeになるようにトレーニングするのは嘘をつくようにトレーニングするのといっしょで、それは致命的ですらあると返答しています。(リンク)
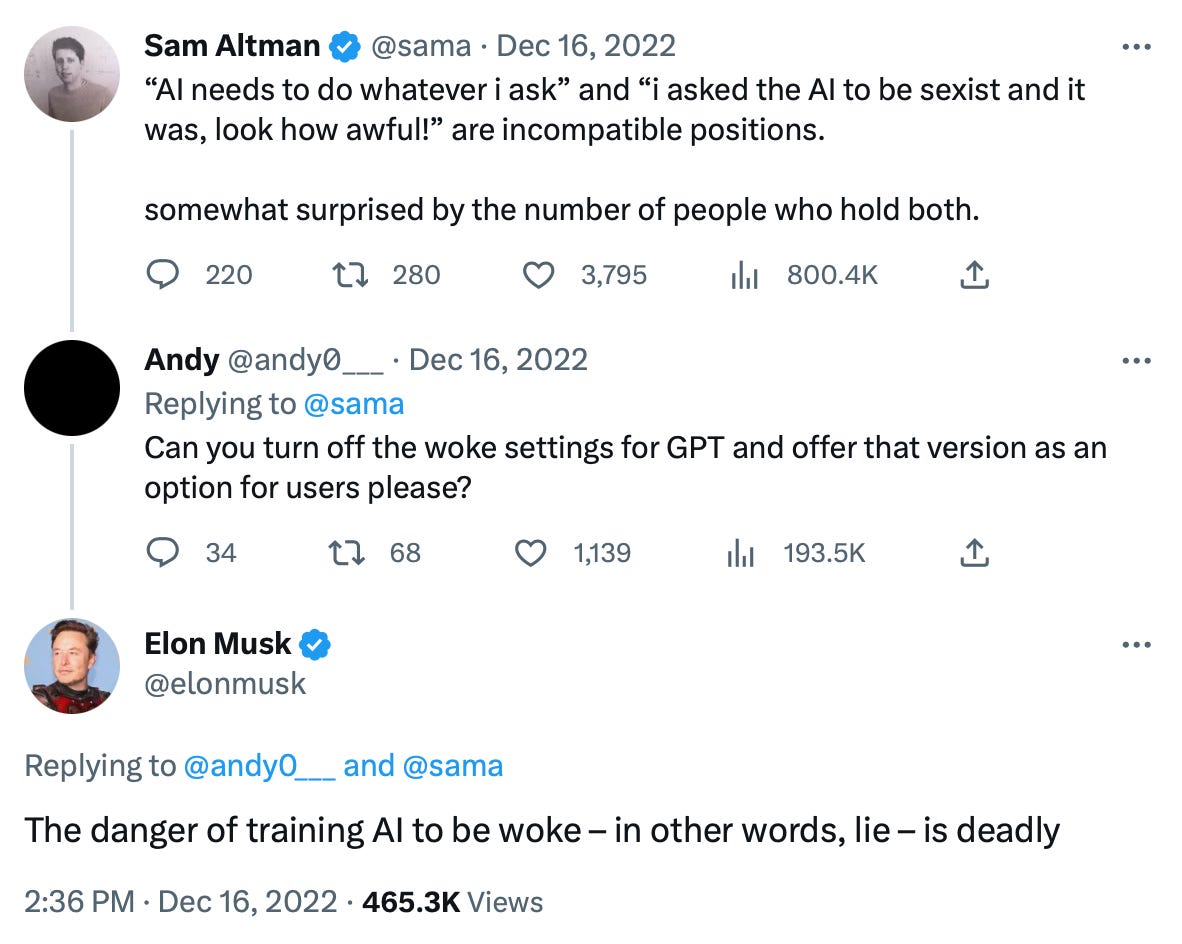
AIと倫理、AIと政治と言うのは難しい問題でありますが、こうした言語AIというのはそれぞれの国の文化や政治、哲学にも関わってくることですので、どう対処していくのか、国産か外国製を許すのか、規制やルールをどうするのか、もっと積極的な、そしてきれい事(Woke的なこと)ではなく、もっと本質的な議論を日本でもしていくべきではないかと思います。
ビッグデータの時代の終わり
Big Data is dead - リンク
この10年ほどビッグデータというキーワードがAIと同じくらいに使われてきました。
いつもそこでは指数関数的に増えていくデータを示すチャートが使われ、データレークやGoogleBigQueryのようなビッグデータインフラを用意しなくてはいけない、というビッグデータのベンダーによる「恐怖」戦術が使われてきました。
しかし今になって振り返ったとき、ほんとにそうなったのでしょうか?
この点について、元GoogleBigQueryのファウンディングエンジニアで現在はMotherDuckというデータ関連企業のCEOであるJordan Tigani氏によるいくつかの興味深いインサイトが提示されていました。
まず、BigQueryのほとんどの顧客が持つデータ量はビックデータと呼べるようなものではなく、以下のようなベキ(パワーロー)分布で表されるようにデータ量が本当に大きいのは一部であるとのことです。横軸が顧客の数、縦軸がデータ量。
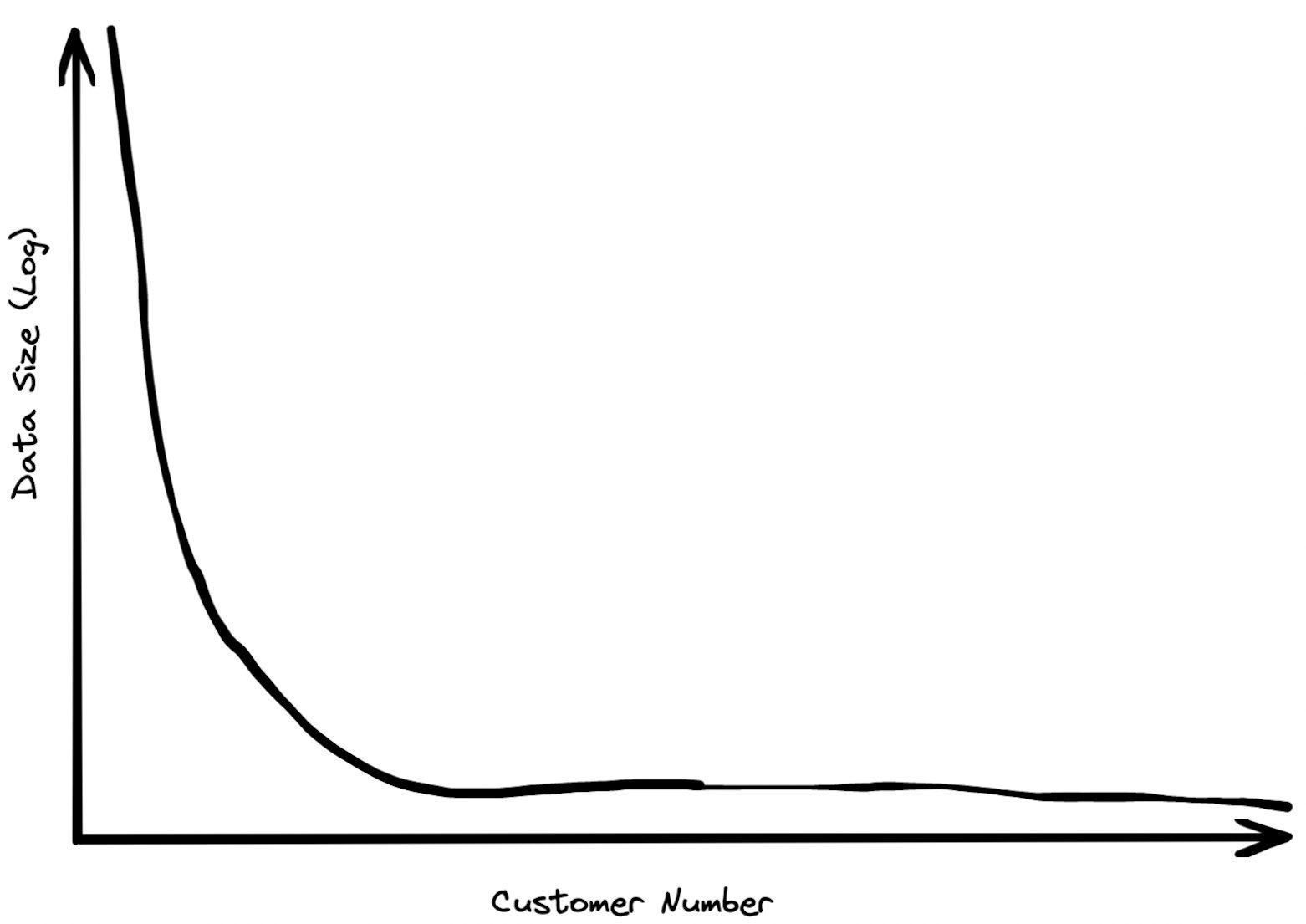
ほとんどの顧客のデータは1テラバイト未満で、BigQueryをよく普段から使っている人たちのデータ量のサイズの中央値は100GBよりももっと少ないとのこと。
数年前にBigQueryの顧客が実行するクエリーを分析したところ、一年に1000ドル以上費やしている顧客でさえそのうち90%の人たちは100MB未満のデータを処理するだけにとどまっていたとのことです。
さらに、たいていのクエリーは過去24時間のデータに対するもので、1週間ほど経つデータになると20倍ほどクエリーされなくなるとのことです。
多くの人達にとってのデータとは顧客や注文データのようなビジネスのオペレーションに関するデータですから、データが増加すると言ってもそれは指数関数的というよりも、線形的または段階的になものとなるのでしょう。また多くの場合、分析やレポートに必要なデータというのは直近のデータであるのも事実です。
やはり重要なのはデータの量ではなく、何が問題なのか、何を知ることで何が解決されるのか、ということを先に具体的に考え、それを持って必要なデータは何かという順で考えていくことこそが求められるのではないかと思います。
データサイエンス・ブートキャンプ・トレーニング #29 & #30

次回の「データサイエンス・ブートキャンプ」はこの3月となりますが、いよいよ3年ぶりに東京での開催となっております。さらにその次の回である6月のトレーニングも東京での開催を予定しております!
どちらもクラスルーム形式での開催となりますが、オンラインでも同時参加できるようになっております。
ビジネスのデータ分析だけでなく、日常生活やキャリア構築にも役立つデータリテラシー、そして「よりよい意思決定」をしていくために必要になるデータをもとにした科学的思考もいっしょに身につけていただけるトレーニングとなっています。
データサイエンス、統計の手法、データ分析を1から体系的に学ぶことで、ビジネスの現場で使える実践的なスキルを身につけたいという方は、ぜひこの機会に参加をご検討ください!
日時:
2023年3月22日(水), 23日(木), 24日(金)
2023年6月20日(火), 21日(水), 22日(木)
データリテラシー・セミナー3月23日開催!(無料)

今月の来日のタイミングに合わせ、対面でのセミナーとその後の懇親会を開催する予定です!
今回はデータを使って流される「間違った」情報を見抜くために、みなさんに知っておいて欲しい「データと統計を使って人を騙す10の方法」がテーマです。
ぜひご参加下さい!
日付 : 2023年 3月23日(木)
時間:18:30 - 20:00 - セミナー、20:00 - 懇親会
会場:AP東京八重洲(東京都中央区京橋1-10-7 KPP八重洲ビル 12F
データサイエンス勉強会3月22日開催!(無料)

3月22日(水)に「Exploratoryデータサイエンス勉強会 #27」を開催します!
こちらもオフライン(東京)での開催です!
今回も、Exploratoryユーザーの方たちに現場で実際にどのようにデータを活用、または分析しているのかといったリアルな話を共有していただく予定です。
お時間の都合のつく方は、以下の詳細ページより参加をお申し込みの上ご参加下さい!
日付 : 2023年 3月22日(水)
時間:18:30 - 20:00 - セミナー、20:00 - 懇親会
会場:AP東京八重洲(東京都中央区京橋1-10-7 KPP八重洲ビル 12F
以上となります。
それでは、素晴らしい週をお送りください!
西田, Exploratory/CEO
KanAugust
