

Exploratory Newsletter Vol. 86
Exploratory Newsletter Vol. 86

“どんなバカでも知ることはできる。重要なのは理解することだ。”
— アルベルト・アインシュタイン
こんにちは、西田です!
少し前に私の住むフロリダのサラソタにハリケーンが陸上したため、避難したり電気やインターネットが止まったりといったかんじでドタバタしていましたが、今週から子どもたちの学校も正常に始まり、いつもどおりの生活に戻ったというかんじです。
私の住むところから南に50キロほど行ったフォートマイヤーズの辺りはハリケーンが直撃し、壊滅的な被害を受けました。この辺りはたまに行くことこも多かったのですが、見慣れたビーチ沿いの光景は今となっては見る影もありません。改めてハリケーンの恐ろしいまでの破壊力を感じました。

しかし同時に、例えばサニベルというとても綺麗なビーチのある島へかかる唯一の橋が破壊されたのですが、その橋はこの短期間にすでに復旧され、現地の人に必要な物資がすでに輸送開始され、復興の方が急ピッチで進んでいます。
ここにポジティブな人間の力や愛というものを感じることができ、人類の将来に希望を持つことができます。
ところで、こうした自然災害が起きると、多くのメディアや政治家は地球温暖化や人間社会の出す二酸化炭素と結びつけたがります。地球温暖化が進んでいるから、自然災害の数が多くなり、威力が強くなり、被害コストが大きくなる、といった具合です。
今回のハリケーンも例に漏れることなく、メディアは散々と地球温暖化に結びつけた報道を繰り返しました。
しかし、自分の手で一度データを取って見てみると、メディアによって伝えられることは真実とはかけ離れていることがわかります。そもそも、ハリケーンと地球温暖化または気候変動の関係はすでにIPCCなどを含めたいくつもの公的な機関によって検証され、この2つの間には関係がない、またはデータを元に有意となる根拠はないという結論さえ出ているのです。
そこで、ハリケーンと地球温暖化に関していかにしてメディアが「嘘」をつくか、データを元にした解説記事を書いてみました。興味のある方はぜひ読んでみてください。
ハリケーンを地球温暖化のせいにするメディアの3つの嘘 - リンク
それでは、以下、データに関する興味深い記事の紹介です。
最近の興味深い英文の記事
Instacartが機械学習を使って検索文字列の最適化を行う仕組み
How Instacart Uses Machine Learning-Driven Autocomplete to Help People Fill Their Carts - リンク
アメリカでは有名なお買い物代行サービスのInstacartがユーザーのエンゲージメントを上げるためにどのようにデータを使って検索の「オートコンプリート」機能を改善しているかについての記事がありました。
Googldeでもそうですが、優れた検索のエクスペリエンスはユーザーがタイプし始めた瞬間から最適な検索対象となるリストをサジェスト(提案)してくれるので、全ての文字列を正確に入力する必要はありません。
Instacartは買い物に最適した検索エクスペリエンスを作り上げるために、1130万ものプロダクトやブランド名をもとに作られた5万7千の単語からなる辞書を持ち、それらを組み合わせた78万5千語に登るパターンをオートコンプリートとして表示しているとのことです。

このオートコンプリート機能を提供するにあたってのいくつかのチャレンジと、それらの解決方法がまとめられていますが、そのうちの1つをここでハイライトします。
検索された文字列とは違うが意味的には同じ文字列
ユーザーがある文字列をタイプすると、全く同じ文字列でなくとも、ユーザーが意図したであろうプロダクトの名前やカテゴリーをサジェストすることは検索機能にとって重要になります。Instacartはここで、検索文字列とプロダクトの関係を事前に学習した検索エムベディングモデルを使っているとのことです。このモデルは過去に検索された文字列とその結果ユーザーがたどり着いた先のプロダクトの組み合わせをもとにスコアされた近似性をもとにしています。
例えば、以下の左側の文字列をユーザーがタイプすると、このモデルは近似性スコアをもとに右側の文字列をサジェストできるようになるので、ユーザーは適したプロダクトを簡単に検索できるようになります。(数値は近似性スコアです。)
Cheese slices → Sliced cheese: 98%
Mayo → Mayonnaise: 97%
Mac cheese → Macaroni cheese: 97%
他にもこの手の検索によくある問題とそれらの解決方法が記事の中で紹介されています。
データサイエンスにおいて見過ごされがちだが重要なソフトスキル
The underestimated importance of soft skills in data science - リンク
データサイエンティストには、データを扱うために要求される技術や分析手法に関する知識といった「ハード」な能力だけでなく、優れたコミュニケーション能力、クリティカル・シンキング、ストーリー性をもたせる力、チームで働くことができる力、適用能力、あなたのブランドに対する知識、知的好奇心、といった「ソフト」な能力も求められます。しかし、これはよく聞くことではあるのですが、多くの人に見逃されがちでもあります。
この記事ではそうした「ソフト」な能力の中でも特に以下の3点に関して強調されていました。
#1 聞く力
これはデータサイエンティストに限らずですが、多くの人は誰かが問題について話し始めると最初の数分で解決法を考え出してしまうものです。そのせいで、相手が話していることを注意深く聞けず、もう一度聞き直さなくてはならないということになってしまいます。
重要なのは、まずは問題の正確な理解です。何が問題なのかを理解することなしに正しい解決法を考え出すのは不可能です。
#2. 細部に注意を払う
取るに足らないと思ったことが重要だったりすることはよくあります。データの中にある異常なものに気づき、伝えようとするストーリーとデータの間のギャップに気づき、レポートの中で使われている全てのチャート間で使われている色の選択が統一されていないことに気づく、などといったことは、些細なことのようで実は仕事のクオリティだけでなく、その後の作業行程にも大きく影響していくものです。
#3. 意思決定
何かの意思決定をするために、分析したり思考したりする時間が後2週間は必要だというときに、現実には後2時間しかないということはよくあります。例えば、予測モデルを作るためのベストな変数を選ぶというのは、簡単な意思決定のようです。というのも、モダンなツールを使えば「変数重要度」を使って重要な変数をすぐに出すことができるからです。
しかし実際には、それらの変数は全て重要なのか、擬似相関のような問題はないのか、そうした変数を使って予測モデルを作ったとしたら、それはどれだけ信頼できるのか、もし間違っていたらどういう影響があるのか、といったことを理解することなしには意思決定できません。もちろん、実際には時間は永遠にあるわけではないので、限られた時間と情報の中で、意思決定をしなくてはいけないという制約があります。
限られた時間とデータを使って、意思決定に必要となる情報を最大限用意する、この視点はデータ分析の際に重要となりますね。
中国政府、チベット自治区で大規模なDNA収集をしていることが明らかに
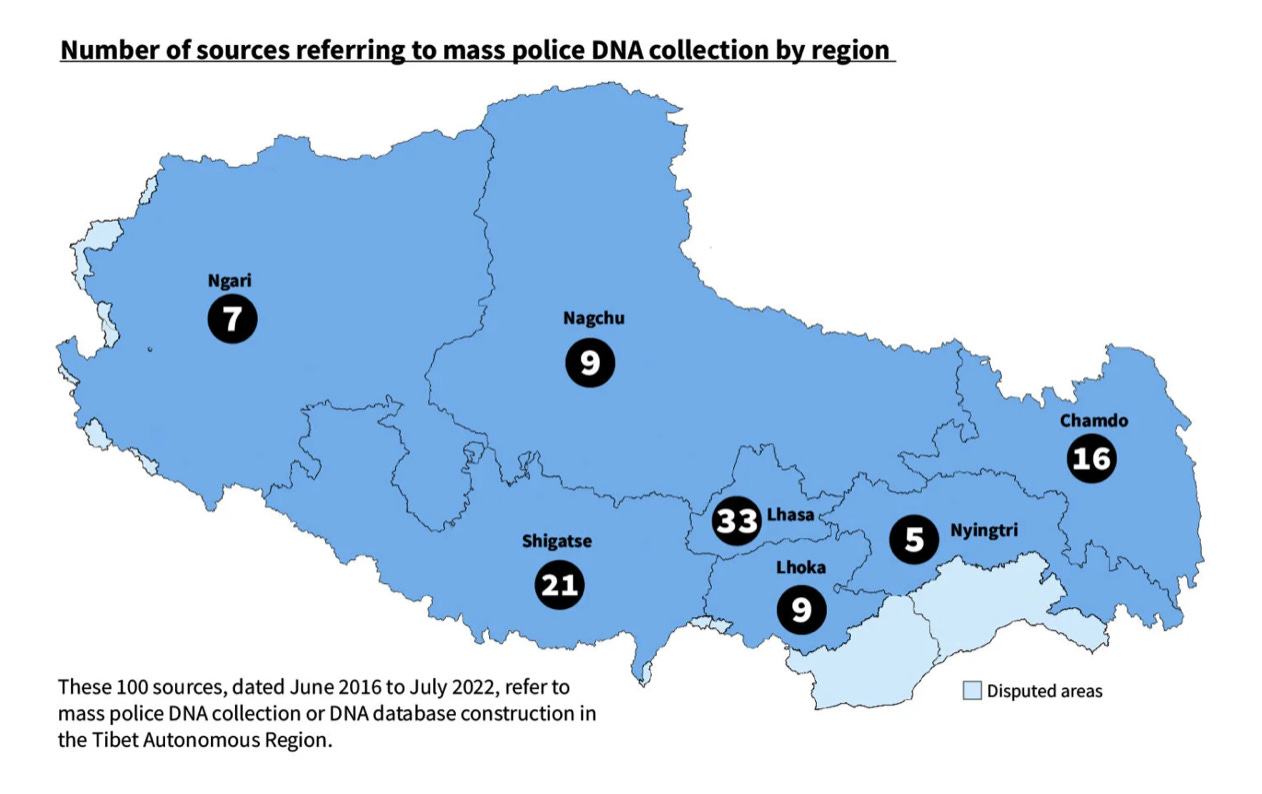
Mass DNA Collection in the Tibet Autonomous Region from 2016–2022 - リンク
2016年から2022年の間に、警察は92万人から120万人ほどのチベット人のDNAサンプルを集めたと言われています。それは366万人いるチベットの総人口の25%から33%に当たる規模になります。
以下はいくつかの地域別の数字です。
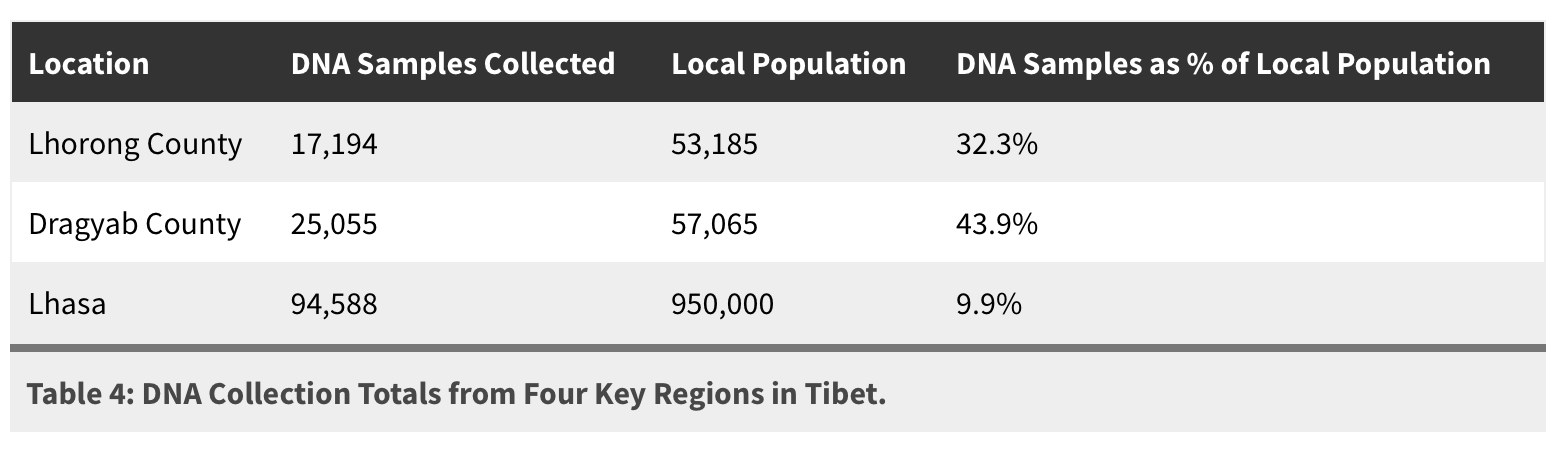
犯罪への対処、不明になっている人を探すため、治安のためという理由でDNAサンプルが集められることが多いようですが、仏教の僧侶などもターゲットにされているとのことです。
ピーター・ティールが前に言っていたことですが、AIは中央集権的な性質を持っているので中国の共産主義政府のような中央集権的な政府がより得意とするものです。このように大規模にかつ強制的にチベット人などのDNAサンプルデータを収集し、そうしたデータを元により「性能の良い」AIを作り上げるというのは、その1つの例だと思います。
もちろん「性能の良い」AIとは市民にとってではなく、政府にとってということです。そして、多くの場合市民はそうしたAIが何に使われているか知ることもないのです。
コンピュータと情報分野のリサーチサイエンティストの需要は次の10年で21%増加する
アメリカの労働省の統計レポートによるとコンピュータと情報分野のリサーチサイエンティストの需要は次の10年で21%増加するとのことです。データサイエンティストやデータアナリストなどはこの分野に入りますが、これからも引き続き重要な分野であると同時に、しばらくは人手が足りないことが予測されています。
他の全ての産業分野の増加率は平均5%ということなので、21%という数字は大きな数字だと思います。
データサイエンス・ブートキャンプ・トレーニング #29

次回の「データサイエンス・ブートキャンプ」は来年1月の3日間集中コースとなっております。
データサイエンス、統計の手法、データ分析を1から体系的に学ぶことで、ビジネスの現場で使える実践的なスキルを身につけたいという方は、ぜひこの機会に参加をご検討ください!
ビジネスのデータ分析だけでなく、日常生活やキャリア構築にも役立つデータリテラシー、そして「よりよい意思決定」をしていくために必要になるデータをもとにした科学的思考もいっしょに身につけていただけるトレーニングとなっています。
日時: 平日3日間コース: 2023/1/18(水), 19(木), 20(金)
SaaS/サブスク型ビジネスのためのデータ分析トレーニング 12月開催

SaaSやサブスクリプションビジネスの改善に必須である、ビジネス指標(KPI)の定義、コンバージョンやチャーン(解約)の要因分析、さらにそれらの先行指標となるエンゲージメントの計算方法や分析手法といったものを一気にハンズオンを通して学ぶことで、即現場で使えるスキルを身につけていただくためのトレーニングです。
日時: 平日2日間コース: 2022/12/8 (木)、9 (金)
Exploratoryでは現在エンジニアの方を募集中です!
UIを使ってデータサイエンスを簡単に行うことができるExploratoryデスクトップ、そしてデータサイエンスやデータ分析をチームで行っていくためのプラットフォームであるExploratoryサーバーの開発をいっしょに行っていただけるエンジニアの方を、現在募集中です!
興味のある方はぜひ以下のページより詳細をご確認ください!
今週は以上です!
それでは、引き続きよろしくお願いいたします!
西田, Exploratory/CEO
KanAugust
