

Exploratory Newsletter Vol. 83
Exploratory Newsletter Vol. 83

本当の間抜けとは、真実を知り、真実を見た、それにも関わらずまだ嘘を信じ続けることだ。
リチャード・ファインマン、物理学者、ノーベル賞受賞
こんにちは、西田です!
子どもたちの夏休みがようやく終わり、先週から学校の新学期が始まりました。以前住んでいたカリフォルニアだと8月の終わりに学校が始まっていたのですが、ここフロリダでは8月の2週目からの始まりということで、若干不思議な感じです。気候のほうが6月、7月は唸るような暑さだったのが、ここ最近少し落ち着いてきたので、そういった気候の変化に合わせているのかもしれません。
ところで現在アメリカでは、コロナ対策に意味がないことを悟ったのか、それとも諦めたのか、さらに特にオミクロン以降弱毒化した今となっては、みんな一回はコロナかそれに相当するものに罹り、感染してもただの風邪と同じ症状であることを認識したからなのか、何にせよ一般の人は誰も気にしなくなり、「コロナ」という点ではパンデミックが始まる前の2019年当時のような生活に戻って久しくなっています。
国の機関であるCDC(疾病対策予防センター)も感染対策をワクチン接種者と非接種に分けることを辞め、さらにPCR検査も推奨しないと、最近発表しました。こうして、今年4月の飛行機内および空港でのマスク解禁を含め、なし崩し的に「コロナ対策」がアメリカの社会から消えつつあります。フロリダでは2年前から当たり前に行われていたことが、ようやくアメリカとしても当たり前になったというかんじです。
現在日本ではコロナ感染者数(検査陽性者数)が爆発的に伸びているとのことですが、一部の人はいつ終わるのだろうかと不安に思われているかもしれません。しかしこのコロナパンデミックは、「感染者数が減る」からではなく、いずれ社会が感染対策に意味がない、またはデメリットがメリットを上回るということを認識したとき、または人々が「もういいでしょ」と思ったとき、日本でも「コロナ」が終わる時になるのではないかと思います。
つまり、ウイルスが消えて無くなるのではなく、私たちの意識から「ウイルス」が消えて無くなる、そうやってなんとなくパンデミックが終わっていく。アメリカに住んでいると、強く実感します。そういう意味では、日本も後少しでコロナが「終わる」のではないかと思っています。
それでは、今回も以下に興味深い記事の紹介をします。
最近の興味深い英文の記事
なぜ表形式のデータの予測には、ツリー系モデル(ランダムフォレスト、XGBoostなど)の方が深層学習モデルより優れているのか
Why do tree-based models still outperform deep learning on tabular data? - リンク
この10年ほどの間で、深層学習(ディープ・ラーニング)はイメージ、音声、言語のようなデータに対して大きな進化を成し遂げ、今ではこうしたデータに対して予測モデルを作るときの標準となっています。
しかし、私たちが普段手にするビジネスデータは表形式(列と行からなるスプレッドシート、データベースの表など)のデータで、こうしたデータは前述のイメージや音声などのデータとは構造や性質が大きく変わるため、深層学習系のモデルはいい成果を出しにくいというのは前から言われていました。
Exploratoryでも結構前に深層学習系のモデルを試してみたのですが、機械学習または統計学習のアルゴリズムで作った予測モデルに比べると大したことのないモデルしかできず、さらにパフォーマンスがすごく遅いということで、結局製品の方に取り組むことにはならなかったという経験があります。
最近、フランスの研究者たちが深層学習系とツリー系からそれぞれいくつかのアルゴリズムを選び、それらを使って45ほどのデータセットに対して予測モデルを作り、予測精度を比べた結果とそのテスト方法などを論文として公開していました。
まずは結果からですが、全ての予測変数(説明変数)が数値型であるときの、それぞれ分類(カテゴリーを予測、左のチャート)と回帰(数値を予測、右のチャート)の予測精度の比較が以下となっています。
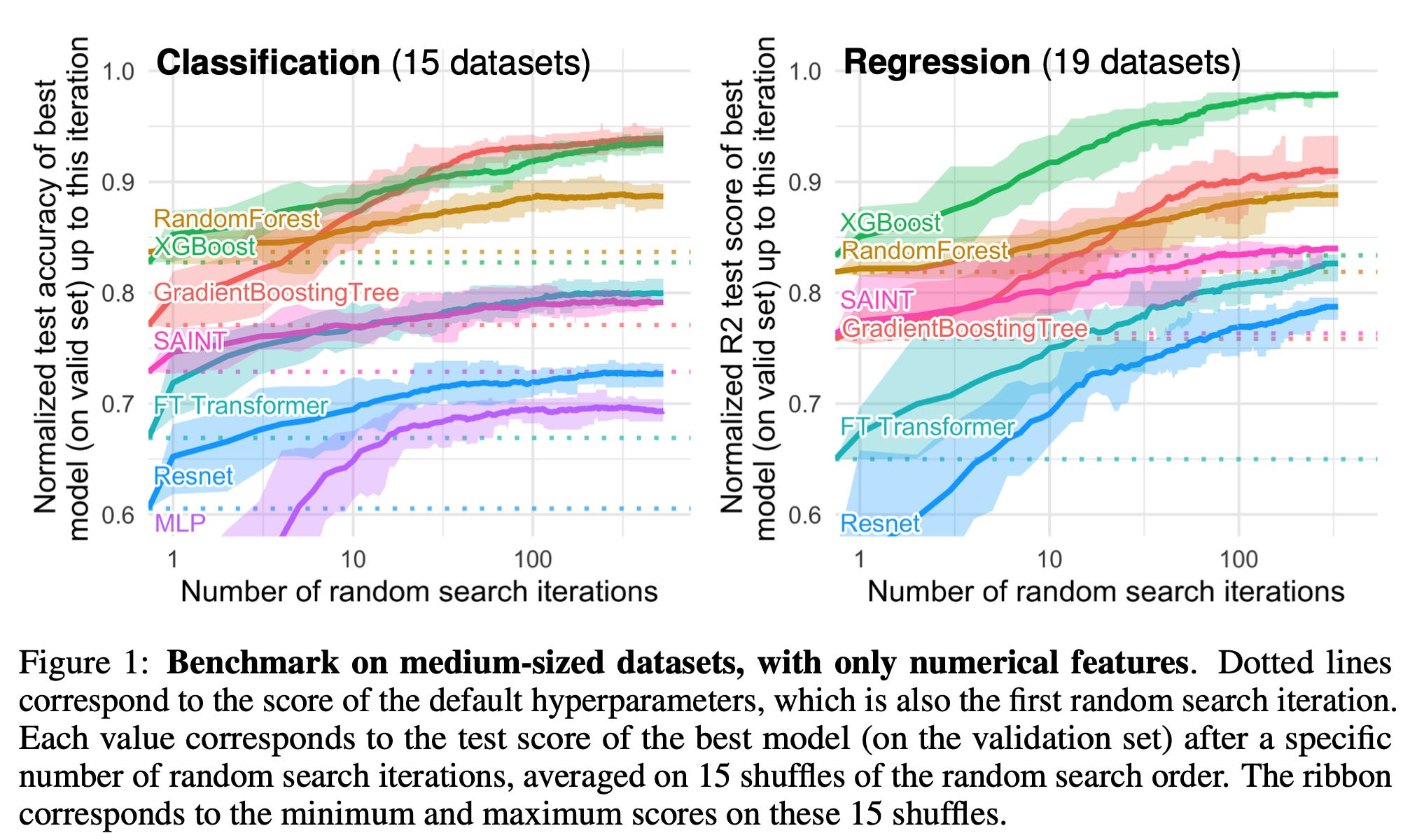
X軸は予測モデルのパラメータ調整の回数で、機械学習のモデル(深層学習とツリー系を含む)は一般的にパラメーターを自動調整していく回数を上げれば上げるほど予測精度は上がっていく傾向があるとされています。
上のチャートを見るとどちらも上位3位を占めるのはツリー系のXGBoost、ランダムフォレスト、Gradient Boosting Treeとなっていて、深層学習系のResnet、FT Transfomerなどはツリー系のモデルと比べ、精度がかなり低いのがわかります。
この傾向は、予測変数(説明変数)が数値型とカテゴリー型の両方を含む場合により顕著になっています。
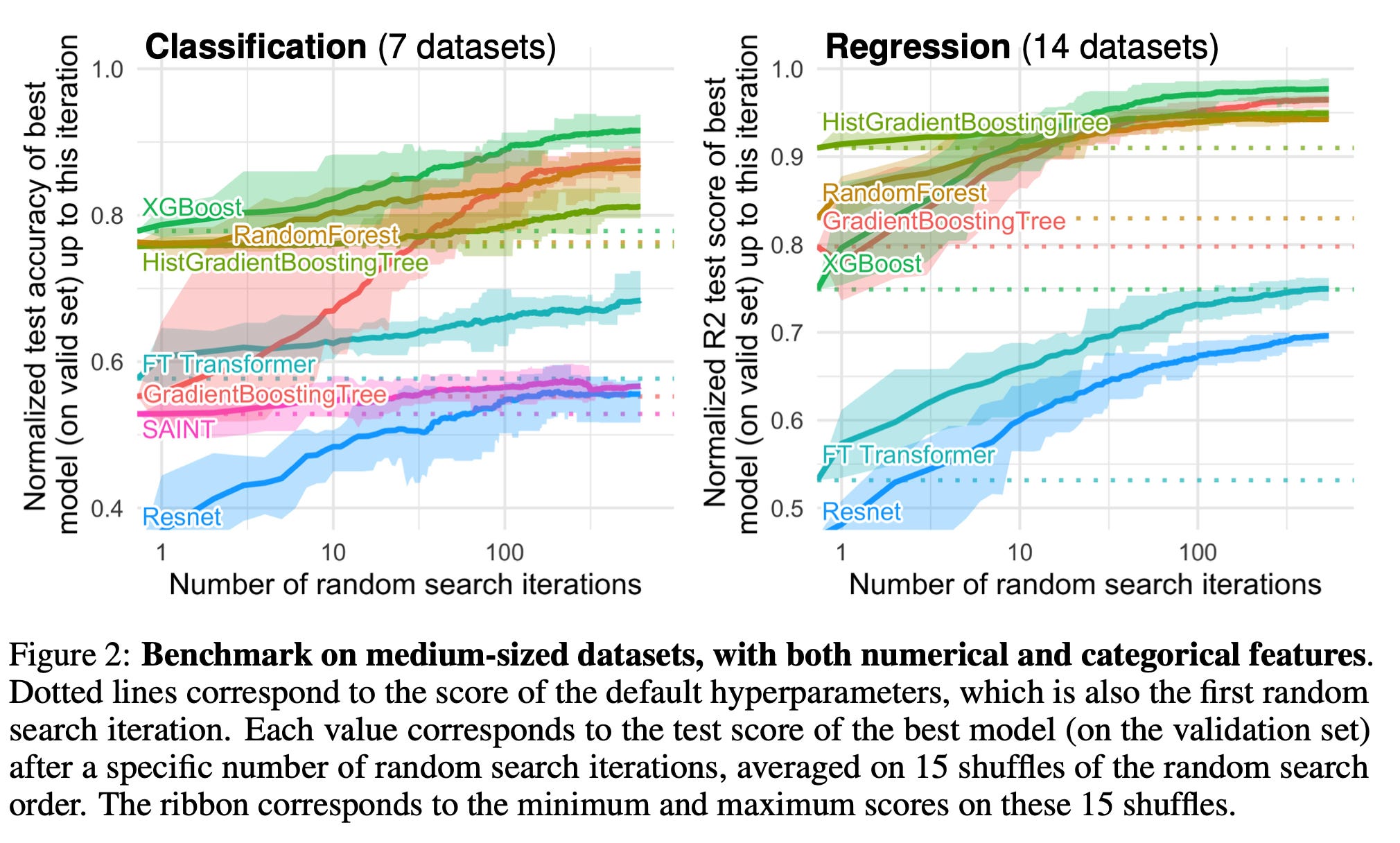
なぜこうした深層学習系のモデルはツリー系のモデルに比べて予測精度が劣るのかという点について、この論文の著者は以下の点を挙げています。
まず最初に目的変数の値が「スムース」でないと深層学習系のモデルは苦しむ。これは予測の対象となる値に外れ値が含まれていたり、その分布が正規分布など予測しやすいものになっていない、または偏っているといったことですが、こうした場合深層学習系のモデルはトレーニングデータにあるそうした不正規な部分を「過学習」してしまうため、テストデータで予測精度を検証すると成果が出なくなります。
また、表形式のデータの場合、予測に役立たない予測変数(説明変数)が含まれていた場合、深層学習系のモデルはそうした変数を無視するのではなく、逆にしっかりと使ってしまい、これもまた「過学習」してしまうため、テストデータで予測精度を検証すると成果が出なくなります。
この2つの理由は、ビジネスデータにとっては致命的です。というのもビジネスで手にするようなデータは普通、目的変数が「スムース」でなく、さらに予測に役立たない列も当たり前のように入っているからです。
逆に、こうした「スムース」でもなく、「役に立たない変数」が入っているデータでも、それなりの予測精度を出すことができるのが、ツリー系の機械学習モデル(XGBoost、ランダムフォレストなど)だと解説されていました。
深層学習系のモデルは、予測モデルを作るのにより多くの時間を要し、ツリー系や統計系のモデルに比べて、モデルの中がどうなっているのかさっぱりわからないというデメリットがあるため、肝心の予測精度が良くないのであれば、使う理由は今のところまったくないということですね。
もちろん、データサイエンスの世界は進化が速いので、この先いつか表形式のデータでも優れた予測精度を出すことができる深層学習系のモデルが出てくるのかもしれません。(こう言われてすでに何年も経っていますが。。。)
モダンなデータチームを作るには
Building Modern Data Teams - リンク
最近よくモダン・データスタックという言葉が使われます。現在のようにオープンソースのツールやテクノロジー、ビッグデータ、クラウド、そしてAIアルゴリズムを使うことが当たり前になった時代にともなうデータ分析のためのデータ基盤ということです。
そしてこうした変化は、もちろん働く人たちの方にも影響を及ぼすということで、「Building Modern Data Teams」というウェブサイトにチームの構成、データチームの戦略やガイドライン、仕事の内容、キャリア構築、などといったことに関して、様々なところで書かれているブログ記事などを集め、わかりやすく分類してまとめてくれています。これからデータ分析チームを作っていきたい、またはデータ分析のキャリアを気づいていきたいという人にとっては有益なウェブサイトだと思います。
スポーツ・アナリティクス
Guide to Sports Analytics - リンク
海外のスポーツとデータに興味のある方に良いニュースがあります。こちらに、主にアメリカのスポーツとなりますが、スポーツに関するデータの取り方、データの加工、可視化の仕方など、様々なチュートリアル(全て英語)のリストがまとめられています。
基本的にはRかPythonというプログラミング言語を使ったものとなっていますが、解説やチュートリアルは、ExploratoryのようなUIツールを使う場合でも参考になると思います。
テスラの自動運転
今から一ヶ月前になりますが、テスラの自動運転部門のトップ、Andrej Karpathyが辞めたとのことです。

現在一般の路上を走るテスラは、かなりの精度での自動運転が可能となっていますが、まだ完全自動運転の域には達していません。
もともとCEOのイーロン・マスクは2018年までには完全自動運転になると言っていましたが、まだ実現されていません。今回の辞職はこれと何か関係があるのでしょうか。
SaaS/サブスクリプションアナリティクストレーニング 8月開催

SaaSやサブスクリプションビジネスの改善に必須である、ビジネス指標(KPI)の定義、コンバージョンやチャーン(解約)の要因分析、さらにそれらの先行指標となるエンゲージメントの計算方法や分析手法といったものを一気にハンズオンを通して学ぶことで、即現場で使えるスキルを身につけていただくためのトレーニングです。
日時: 8月 平日2日間コース: 2022/8/25 (木)、26 (金)
データサイエンス・ブートキャンプ・トレーニング #28

次回の「データサイエンス・ブートキャンプ」は9月の3日間集中コースとなっております。
データサイエンス、統計の手法、データ分析を1から体系的に学ぶことで、ビジネスの現場で使える実践的なスキルを身につけたいという方は、ぜひこの機会に参加をご検討ください!
ビジネスのデータ分析だけでなく、日常生活やキャリア構築にも役立つデータリテラシー、そして「よりよい意思決定」をしていくために必要になるデータをもとにした科学的思考もいっしょに身につけていただけるトレーニングとなっています。
日時:
9月 平日3日間全日コース: 2022/9/14(水), 15(木), 16(金)
Exploratoryでは現在エンジニアの方を募集中です!
UIを使ってデータサイエンスを簡単に行うことができるExploratoryデスクトップ、そしてデータサイエンスやデータ分析をチームで行っていくためのプラットフォームであるExploratoryサーバーの開発をいっしょに行っていただけるエンジニアの方を、現在募集中です!
興味のある方はぜひ以下のページより詳細をご確認ください!
今週は以上です!
それでは、引き続きよろしくお願いいたします!
西田, Exploratory/CEO
KanAugust