

Exploratory Newsletter Vol. 82
Exploratory Newsletter Vol. 82
ローカル最適化、地理情報を元にしたA/Bテスト、厚労省のデータ改竄など。

「闘う政治家」とは、ここ一番、国家のため、国民のためとあれば、批判を恐れず行動する政治家のことである。
「闘わない政治家」とは、「あなたの言うことは正しい」と同調はするものの、けっして批判の矢面に立とうとしない政治家だ。
わたしはつねに「闘う政治家」でありたいと願っている。
それは闇雲に闘うことではない。
「スピーク・フォー・ジャパン」 という国民の声に耳を澄ますことなのである。
安倍晋三
こんにちは、西田です!
先日、安倍元首相が暗殺されたニュースが世界中を飛びまくり、私が住むアメリカでも大きなニュースとなっていました。
まずはこの場を借りて、安倍元首相のご冥福を心よりお祈りしたいと思います。
もちろん、この非情な出来事に対して驚き、悲しみ、怒り、不安、様々な感情が沸き起こりますが、1つだけポジティブな話をここでしたいと思います。
これは、私がアメリカに長く住んでいるため、日本に住み日本のメディアにしか触れていない方たちとは若干異なるようなのですが、彼は間違いなく世界中のリーダー、そして民衆から愛された、日本においては稀有なリーダーでありました。
ここでは、このニュースレターの趣旨と異なるため詳細については書きませんが、その代わりに以下の3つを紹介したいと思います。
現在の国際情勢からはもう想像することもできませんが、少し前までは、アメリカ、中国、ロシア、インド、ブラジル、ドイツ、カナダ、サウジアラビア、などと言った国の首脳が集まり、笑顔を共有する、そんな時代がありました。そして、そうした場を取り持つことが多かったのが安倍元首相でした。

また、将来、人口とともに経済においても中国を抜いていくであろうと言われているインドとの関係を歴史的なレベルで強化されました。そのインドのモディ首相が安倍元首相との関係を振り返る個人的なエッセイ(日本語版)をこの度書かれております。

インドでは本日7月9日を国家を挙げて喪に服すとのことです。
最後に、ブラジルのボルソナロ大統領とも大変親しい関係を築かれておりましたが、ブラジルでは日本国民への敬意と安倍元首相との友情を示すために3日間、国を挙げて喪に服すとのことです。
君が代を流してのセレモニーの一部が以下となります。

以上となりますが、私がこのデータに関するトピックをまとめたニュースレターを日本向けに出したり、日本向けにデータに関するトレーニングを提供したりしているのは、日本にもっとデータを使える人が増えることで、日本の企業や組織がもっと世界をリードしていけるようになればいいなと思っているからです。
そういう意味でも、日本の素晴らしさを世界に向けて行動で示してくれた、日本の偉大な指導者に改めて感謝したいと思います。
それでは、本分に戻り、今回もいつものようにいくつかの記事を紹介したいと思います!
最近の興味深い英文の記事
ローカル(部分的)最適化
Locally Optimal - リンク
Exploratoryでもサポートしている、データサイエンスの世界では有名な時系列予測のアルゴリズムにProphetというのがあるのですが、これを作った元FacebookのSean Tylerという人が新しく始めたニュースレターの1回目の記事にA/Bテストに関する「ローカル最適化」の問題について書いていました。
以下、引用です。
===
企業で最も価値のあるデータの活用の仕方の一つがA/Bテストである。それは簡単にまとめるとこんな感じで行われます。
誰かがプロダクトに関するアイデアを持ちこみ、そのアイデアをプロトタイプとして作り、それをテストする環境を作り、ランダムに振り分けたユーザー達に対して数日または数週間ほどテストを流す。その後に、ある基準を元にそのアイデアによるベネフィットがどれくらいあるのかを推定し、そのアイデアはプロダクトに変更として加えるだけのベネフィットがあるかどうかを判断する。
これらは大きく以下の3つのフェーズにまとめることができます。
アイデアを思いつき、それをプロトタイプとして作る。
テストを流してデータを集める。
集まったデータを分析し、何をするか意思決定する。
ある程度の規模の会社であればたくさんのプロダクトマネージャーやエンジニアが1番目のフェーズをやっていて、たくさんのアイデアを毎日テストしています。私は、当時ある程度しっかりしたプロダクトを担当していたので、比較的小さい改善をもたらすアイデアが多かったです。この場合、データ分析を行う人は3番めのフェーズに対して大きく貢献することができます。多くの場合、こうした改善に関する効果というのは小さなもので、それがほんとうに改善につながるのかどうかの判断は注意深く行う必要があるからです。
私がFacebookの後、Lyftに来た時、マーケットプレース・ラボの所長の仕事を引き継いだのですが、その時に元所長に「なぜ統計的な問題にもっと労力を費やさなかったのか」と尋ねました。返ってきた答えは「私たちがやってたようなプロジェクトは成功したときっていうのは、統計的な分析をしなくてもわかるレベルだったんだ。」でした。
===
引用終わり。
プロダクト、またはスタートアップは最初のゼロから1という価値をゼロベースから作り上げる段階、そして1から10という他の人にも提供できる価値を作る段階、そしてその後どんどんとスケールさせていく段階といったような、成長するにつれていくつかの段階を踏んでいくことになります。
そのため、それぞれの段階ではデータの使い方も異なります。最初の頃はまずはユーザーがいるのか、使っているのか、お金は後どれくらい残っているのかといった基本的なことを数値でモニターするのに対して、ある程度スケールし始め、ユーザーの数も増え、収集することのできるデータも増え始めると、そこでA/Bテストを行い、その結果を統計的に分析、判断していくことが重要となってきます。
こうした違いを認識した上で、最適なデータ人材を雇わないと、雇った人にとっても雇われた人にとっても面白くないことになってしまう、というのはよくある話です。
Instacartの地理情報に基づいたA/BテストとDifference-in-Difference分析
Geo-based AB Testing and Difference-in-Difference Analysis in Instacart Catalog - リンク
アメリカではスーパーなどからの食品のデリバリーを行うサービスを提供しているInstacartという会社がありますが、そのデータサイエンスチームがどのようにA/Bテストを行っているのか、またその結果の分析の仕方に関する記事を出していました。
商品の名前や紹介の仕方などをA/Bテストする際に、ユーザーをランダムに2つのグループに振り分けるのではなく、食料品店やスーパーを地理情報を元にランダムに2つのグループに振り分けているとのことです。
そうすることでデータベースでのデータの持ち方、さらにシステム上での商品名や紹介の仕方のアップデートを簡単に効率的に行うことができるからという理由のようです。
ただ、このようなかたちでグループを分けてしまうと、分けられた食料品店やスーパーの顧客の属性に大きな違いが出てくるため、2つのグループにはバイアス(偏り)が入ってしまいます。
そこでDifference-in-Differenceという分析手法を使い、2つのグループのもともとの時間軸でのトレンドを出した上で、A/Bテストを行う前と後、つまり何らかの変更を加える前と後でのトレンドの変化というものを2つのグループ間で比べ、そうした変更の効果を推定するといったことをしているとのことです。
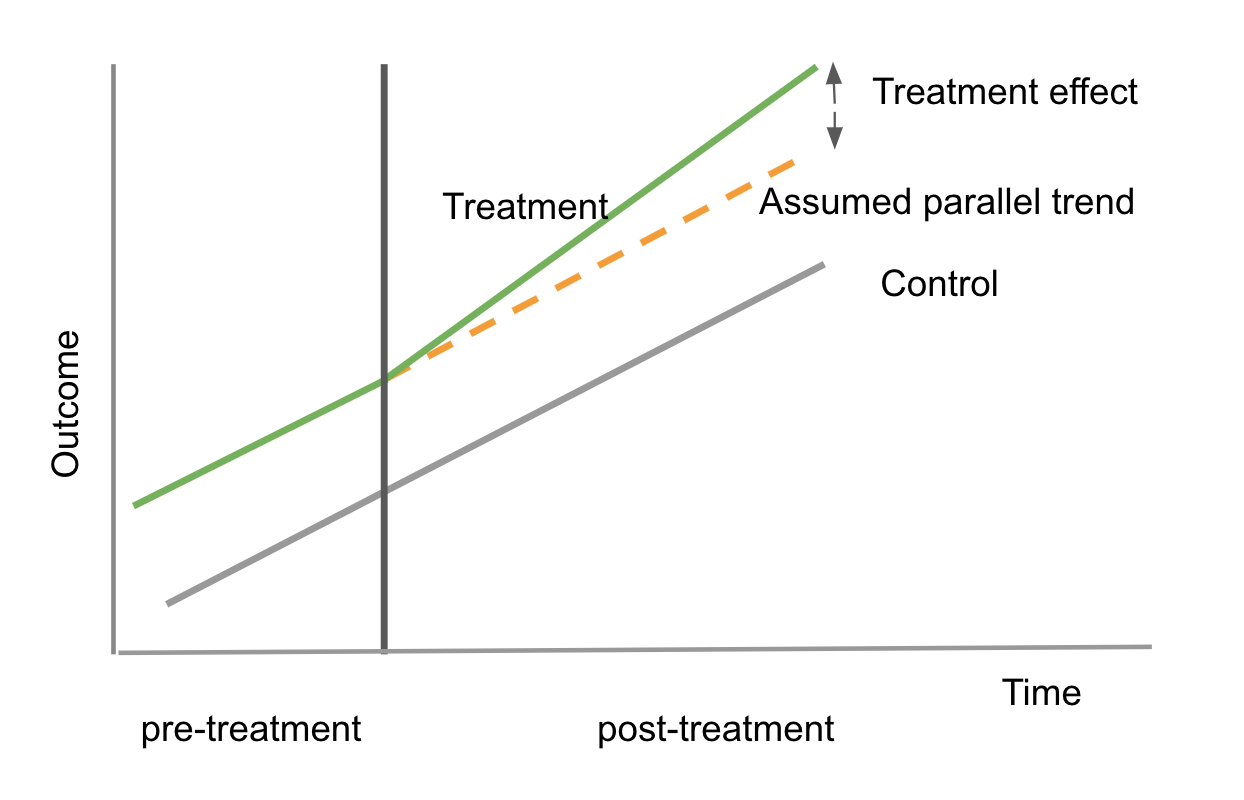
上の図は、2つのグループをコントロールグループ(変更を加えていないページを見せているグループ)とトリートメントグループ(緑、変更を加えたページを見せているグループ)に分け、違いを観察しています。
厚労省のワクチン接種とコロナ感染に関するデータ改竄問題
こちらは、日本のデータに関することですが、重要なのでこちらで取り上げます。
ちょっと前になりますが、厚労省が、ワクチンを摂取したが接種日を覚えていないという人たちを「未接種」としてカウントした結果、未接種者のほうが接種者よりもコロナに感染しやすいという結論を導き出し、さらにはそれを全国各地で広報し続けたという不祥事がありました。
例え裏にどういう理由があったにせよ、180度変わってしまう結論が出てしまうことを承知でデータ操作をしてしまったわけですが、データに関わるものとして、これだけはやってはいけないことだと思います。
改竄されたデータから導かれた結論を元に意思決定をしてしまった人達に対する裏切りであるので、このこと自体がひどいことですが、長期的に見て、当事者である厚労省が二度と信用されなくなってしまうという問題、さらに、世間一般にデータに対する不信感が植え付けられてしまうという問題があります。
私たちがふだん手にする多くのもの(プロダクト、サービス、製薬、情報など)の多くは科学的な発見と検証の上に成り立っています。そして全ての科学の検証はデータの上に成り立っているわけですから、このデータが信頼されなくなってしまうと、その後がありません。
科学者が改竄したデータをもとに論文を発表したことがバレてしまえばその人のキャリアはほぼ終わってしまうでしょう。そのレベルのことを政府が先導してやってしまった訳ですから、これは科学に対する、データサイエンスに対する挑戦でもあります。
今回のワクチンに関しては様々な意見、見方があります。それでも現時点では、ある一定のリスクがあることは広く認められるようになっています。そこでリスクとベネフィットを天秤にかけ各自が判断していく必要があります。であるからこそ、データの扱い、さらにデータからどう結論を導くのかに関しては、謙虚に、そして真摯に取り組んでもらわなければ困ります。それが、国民の命を預かる政府であれば、なおさらだと思います。
実は、こういったことは企業、組織の中ではよく行われていたりします。つまり、自分の都合の良い結論を導くために、データに手を入れるということです。今回の厚労省のように、データのラベル自体を付け替えるといった悪質なものでなくとも、一部をデータから外すといった軽いものまで様々です。宣伝、広告の世界ではよくあることです。
しかし、今回の厚労省のデータ改竄問題は、人の健康や命に関わる情報である点、そしてさらに国民の命を預かり、国民の利益を代表するはずの政府であるという点から、ある特定のメッセージを伝えるためにデータをいじってしまったでは許されません。
人間ですので、このときはデータを改竄してもいいが、このときはだめ、などとうまく切り替えることのできる人はなかなかいないと思います。それだけに、データに関わる人間であれば、普段から「自分に都合の良い結論を導くために、データを改竄してしまっていないか」という質問は絶えず自分に問いかけ続けるべきだと思います。
今週のチャート
さきほど、データ改竄していたと紹介した日本の厚労省の出している死亡者数のデータを、各年の推移を月ごとに比べれるように可視化をしたものが以下のチャートです。(このデータは改竄されてないと思うのですが、どうなのでしょうか。)
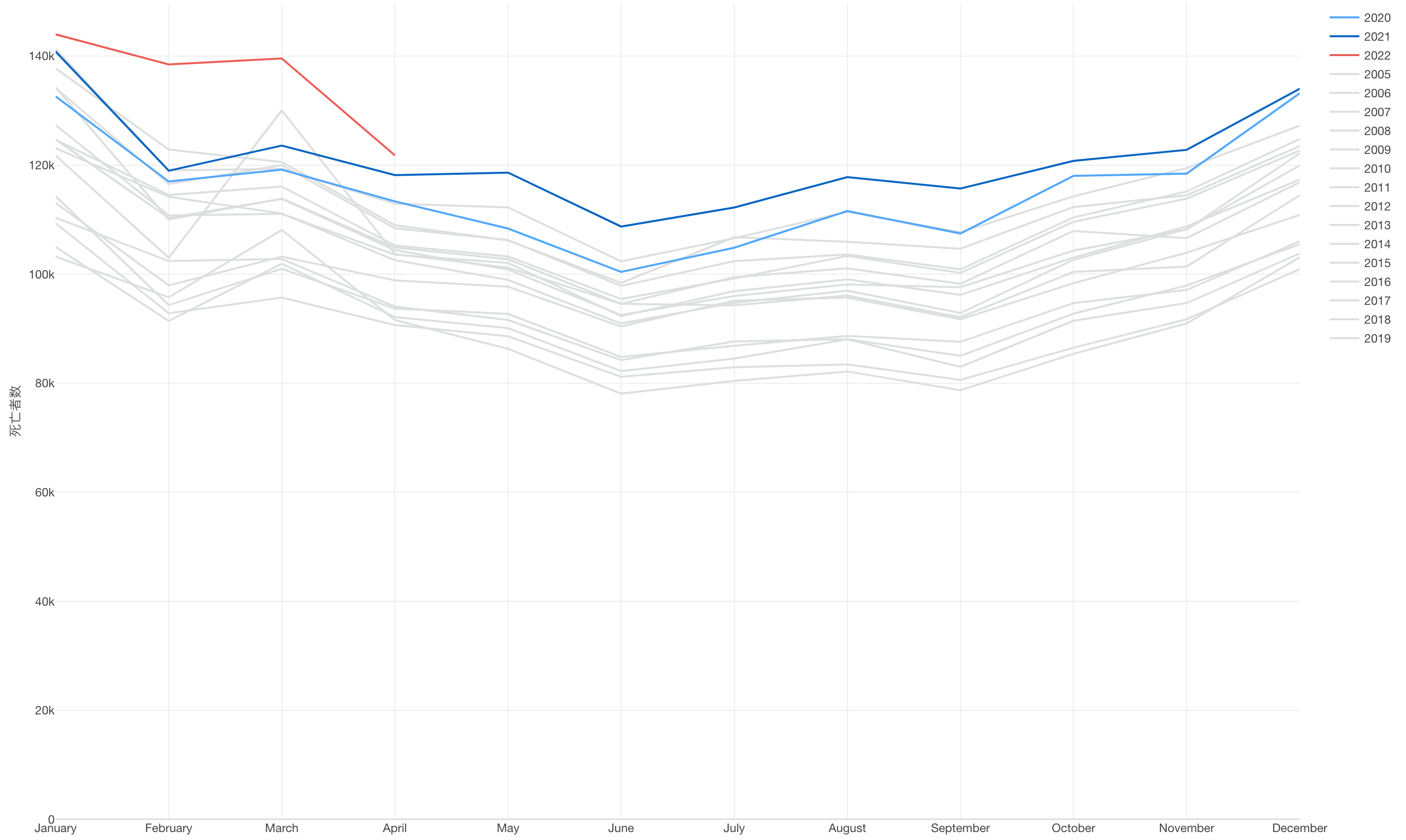
注目したいのは、今年2022年(赤)の特に2月、3月の死亡者数が例年に比べて大きく多いという点です。本来であれば死亡者数が例年に比べて多くなると思われた、コロナ感染が広まり始めた2020年(水色)の死亡者数は例年のトレンドから大きく離れることはありませんでした。
厚労省の出すデータなので信頼できるかどうかはさておき、もしこれが正しい数値なのであれば、これまで様々な感染予防対策を国民に強いてきた厚労省、そして政府はしっかりと国民に何が起きているのかを説明すべきだと思います。
データ:
SaaS/サブスクリプションアナリティクストレーニング 8月開催

SaaSやサブスクリプションビジネスの改善に必須である、ビジネス指標(KPI)の定義、コンバージョンやチャーン(解約)の要因分析、さらにそれらの先行指標となるエンゲージメントの計算方法や分析手法といったものを一気にハンズオンを通して学ぶことで、即現場で使えるスキルを身につけていただくためのトレーニングです。
日時: 8月 平日2日間コース: 2022/8/25 (木)、26 (金)
アンケートデータ分析トレーニング 8月開催

アンケートデータを使って顧客をより深く、多面的に理解するために必要なデータの加工、可視化、そして分析手法を基礎から効率的に学び、現場で使えるスキルを身につけていただくためのトレーニングです。
日時: 8月 平日1日間コース: 2022/8/19(金)
データラングリング・トレーニング 8月開催
「データ分析の80%の時間はデータの加工や整形に費やされている」とはよく言われることです。そこで、データを自由自在に操るためのデータラングリングの手法を1から体系的に、より効果的に身につけていただくことを目的とした、2日間コースのトレーニングです。
日時: 8月 平日2日間コース: 2022/8/9(火), 10(水)
今週は以上です!
それでは、引き続きよろしくお願いいたします!
西田, Exploratory/CEO
KanAugust