

Exploratory Newsletter Vol. 76
Exploratory Newsletter Vol. 76
意思決定ドリブンとデータドリブン、データファースト企業、など。

“The problem with computers is all they can do is provide answers.”
コンピューターの問題は、答えを出すことしかできないということだ。
パブロ・ピカソ、画家
こんにちは、Exploratoryの西田です!
現在日本はオミクロンによるパニックによって政治、社会、経済が混乱しているように見えます。私の住むフロリダは日本と比べて、感染者数、死亡者数ともにあまり変わりませんが、市民の生活はコロナ前の日常に戻っています。
日本ではいまだに感染者数、さらには最近では「濃厚接触者数」という不思議な指標まで使われ、結果こうした数字に政府や公的機関が振り回されているようですが、これは市民の幸せという点から見て本当に妥当なのでしょうか。
フロリダの政府も日本の政府もデータや「指標」を使っています。しかし、対策には大きな差が現れ、結果として市民の生活には大きな違いがあります。なぜこのような違いが生まれるのでしょうか。
「文化の違い」を含め様々な説明があると思いますが、私は意思決定の際のデータの使い方に違いがあるのではないかと思っています。そこで、今回は多くの人がはまってしまう「データドリブンの罠」に関する話を紹介したいと思います。
それでは、今週もいってみましょう!
最近の興味深い英文の記事
データドリブンではなく、意思決定ドリブンであるべき
Be Decision-Driven Not Data-Driven - リンク
「データを使って判断しよう」と多くの組織やチームが意気込むのですが、おかしな方向に向かってしまうことがよくあります。
それは以前から言っていることですが、多くの人たちが「データドリブンの罠」にはまってしまうからです。データを使うのは素晴らしいことですが、データが神様のようになってしまい、数字に踊らされるようになってしまっては元も子もありません。
なぜデータドリブンではなくて、データインフォームドであるべきか - リンク
そこで、今回は最近出ていた「Be Decision-Driven, Not Data-Driven」という記事が「意思決定ドリブン」という言葉を使って、データドリブンとの対比をうまく説明していたのでここで簡単に紹介したいと思います。
以下、要約。

家を建てるときには、設計者、デザイナー、建設する人、配管工事をする人などがジャズを演奏するかのようにいっしょになって仕事を進めていく必要があります。データ分析のプロジェクトとはまさにこの家を建てるようなもので、専門家のアドバイスに助けられながらではありますが、家の持ち主こそが最終的な意思決定者なのです。
#1 データではなく、質問からスタートする
意思決定ドリブンチームは意思決定者といっしょに質問を構築したり、前提が正しいかどうか議論したりすることにより多くの時間を使います。
#2 データサイエンティストではなく、意思決定者がプロジェクトを引っ張る
家を建てるときには家を建てる人がどういう家にしたいのか決めるのであって、それは建設者、設計者、配管工事を行う人たちの仕事ではありません。彼らは専門分野に関しての意見や仕事を提供するのみです。
#3 知ってることより、知らないことに思いを巡らす
意思決定ドリブン型のチームは知ってることより、知らないことを考えることにより多くの時間を費やします。例えば小売業の場合、典型的なデータドリブンなプロジェクトは既存のロイヤリティプログラムをどう最適化するかということにフォーカスします。しかし、意思決定ドリブン型であれば、そもそも何が顧客を満足させるのか、顧客の様子はどのように変わってきているのか、それはなぜか、といったことを探索します。
#4 新しいデータ
データドリブン型のチームはすでにある箱の中で考えがちで、すでにあるデータの有効な活用の仕方を考えます。しかし、意思決定することを重視するチームは、そこにない、または必要となるデータが何かを先に考えます。そのためには、アンケート調査のデザイン、シミュレーション、第三者機関などを含めた外部から得られるデータを探すといったことにより多くの時間を使います。
要約終わり。
コロナでもそうですが、「感染者数」、「濃厚接触者数」という数字に踊らされるのではなく、なぜ感染者数が増えたら問題なのか、コロナの何が問題なのか、それは誰にとっても問題なのか、そもそも何が社会にとって最も重要なのか、といった質問を構築していくことが求められます。そして、こうした質問に答えるためにはデータを集め、観察し、検証し、さらにデータを集めるといったことが必要になります。
そしてこういった様々な社会的な問題を調整することができるのは政治家であって、そこでリーダーシップを発揮することなく、ある特定分野の専門家たちの言うなりになっていたのでは、いつまでたっても社会にとって本当に重要な問題を解決することができないばかりか、新しい余計な問題を作り出してしまうことになってしまいかねません。
この2年間のコロナによる政治的な混乱は、私たちにデータを使って意思決定をするとはどういうことなのかを考えるうえで貴重な機会を与えてくれました。無駄にすることなく、しっかりとこの経験から学んでいきたいものです。
データ関連の人員とエンジニアの数の比率 - ヨーロッパのテック企業
Data to engineers ratio: A deep dive into 50 top European tech companies - Link
世界中でデータ関連の仕事が増えるに従い、データ関連の人材の採用熱が以前に比べさらに高まっています。それはエンジニア職の採用数に迫ってきているほどです。
以下は、ヨーロッパのテック関連企業トップ50におけるデータ関連職の採用募集数がエンジニア職の採用募集数に比べてどれだけの割合かを表したものです。
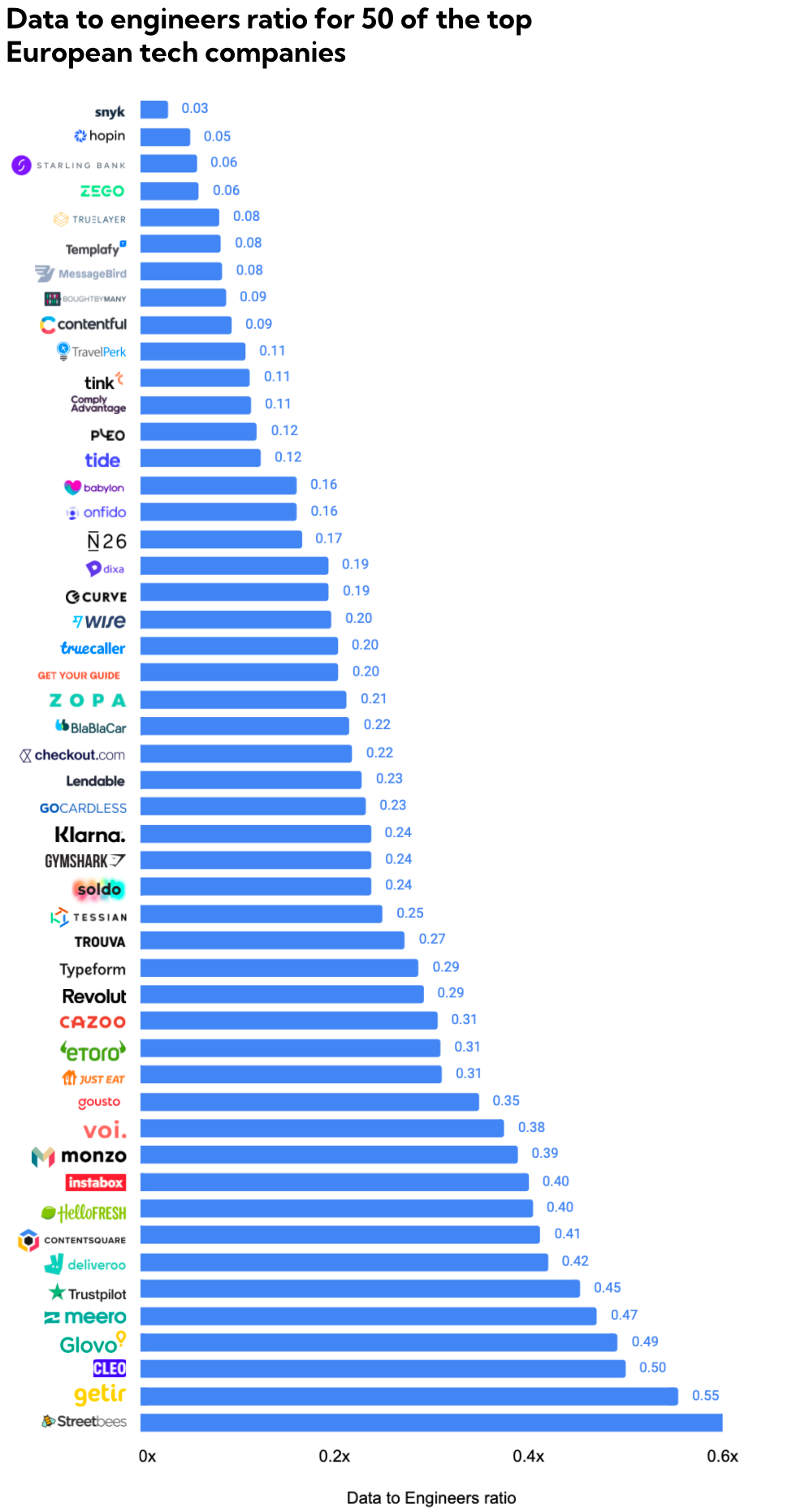
多いところでは、エンジニア職募集数の半分にあたる数のデータ関連職が現在募集中とのことです。
現在、営業、マーケティング、オペレーション、プロダクトチーム、全てがデータを使って意思決定、改善していくことが求められています。そのため扱うデータの種類はより多くなり、量はより大きくなり、その構造や関係はより複雑になるため、データチームにはより多くのことが期待されます。
うまくいっている企業ではすでにビジネスを行うのに必須な形でデータを活用しています。例えば、B2Bのような企業であれば、KPIやダッシュボードをもとに意思決定をしていったり、ビジネスの問題を解決するためのヒントを探すためにセルフサービスというかたちで誰もがデータを探索できる環境を用意したりしています。
また、マーケットプレイスなど、データを組み込んだサービスを提供するタイプの企業であれば、機械学習の予測モデルによるサービスの最適化や自動化であったり、サービスの改善のためのA/Bテストであったり、といった具合です。
つまり、現在のビジネス、特にスタートアップやテック企業にとってはデータを使えるか使えないかは生死に関わることです。
ちょっと前までは、こうした企業の生死を分けるものはテクノロジー、とくにソフトウェアでした。しかし、今日ではデータです。
例えば、犬の散歩の代行サービスを提供するスタートアップを始めると考えてみましょう。もちろんソフトウェアも重要なのですが、飼い主と散歩代行者のマッチング、散歩代行者が複数の犬をピックアップするための道のりの最適化、それぞれの顧客のタイプや時間帯によっての価格の最適化、需要の予測、不正を行う人の検知、などこうしたことに機械学習のモデルやデータを使わないなんてことは考えられません。
データ関連職がどれだけ今ホットかを考えるときにもう一つ面白いチャートがあります。以下は、横軸にデータ職とエンジニア職の割合、縦軸にはデザイン職とエンジニア職の割合、その交わるところに先程のヨーロッパのテック企業トップ50を置いたものです。
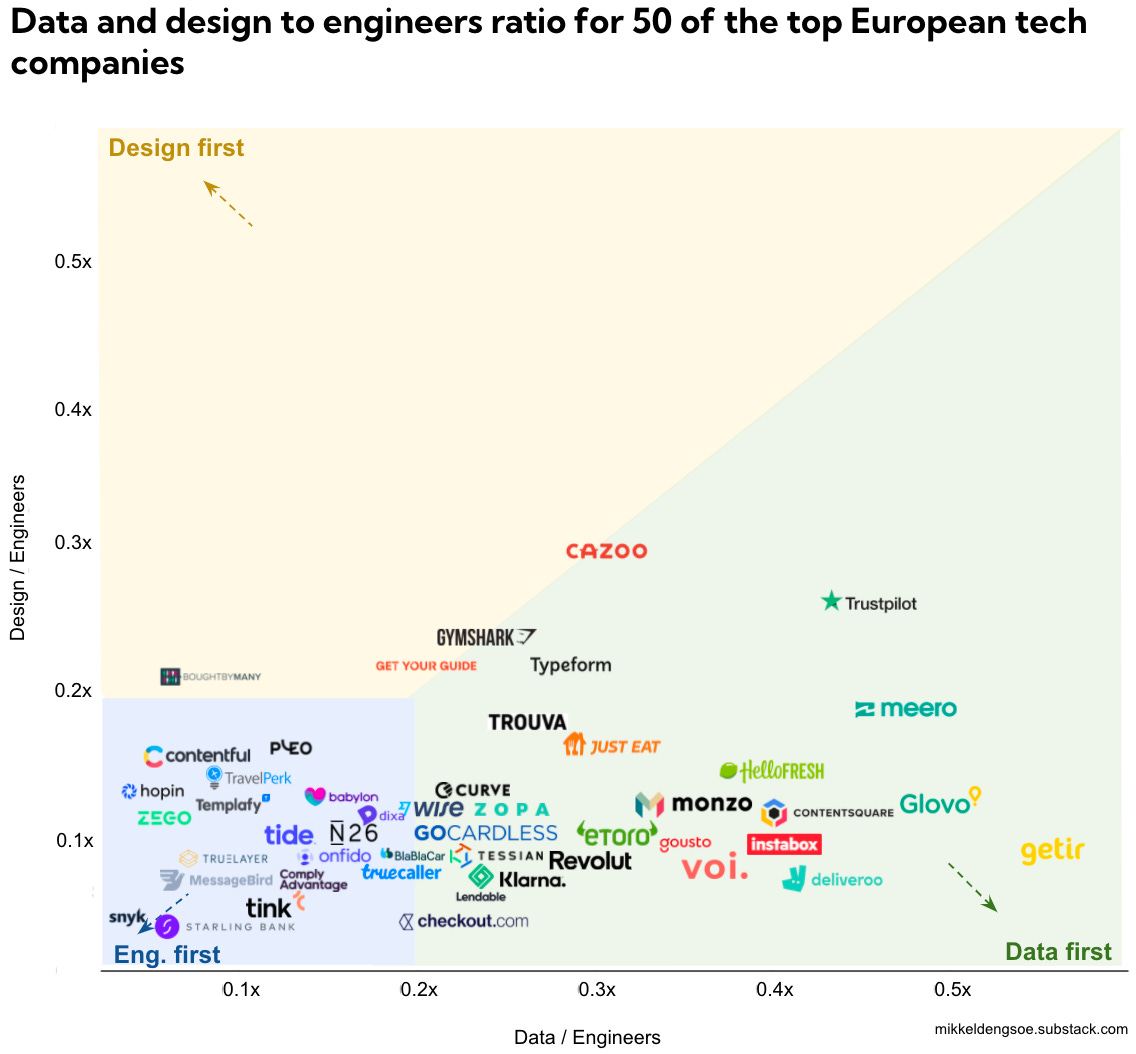
左下の青いところは、両方とも同じくらいの比率で、データ職もデザイン職もエンジニア職の2割以下です。
しかし、右の方にある緑のところにある企業はデザイン職の比率は同じ2割以下ですが、データ職は2割から5割ほどです。
つまり、データ職のほうがより多いということです。ここ10年ほどは「デザインファースト」なんて言葉もありましたが、そういう意味では現在は「データファースト」と言えるのかもしれません。
アメリカは政党によって失業率に大きな差が出る
アメリカでは知事や議会が共和党よりか民主党よりかによって市民の生活には大きな違いが出てきます。そのことについてこちらにツイートしました。


私の住むフロリダ(共和党より)は一昨年、2020年の9月には全ての規制を取り払いそれ以来ずっと規制なしです。逆に以前住んでいたカリフォルニア(圧倒的に民主党より)では未だに様々な形の規制(マスク強制、マスクのタイプの指定、ワクチンの強制、集会やイベントの規制、など)が行われています。
政府が大きくなると無駄と腐敗がおきかねない、多くの場合政府は地域や現場のことを把握できてない、政府は間違っていることがある、といったことで共和党は小さな政府を求め、問題があったときには地域やコミュニティ、個人に解決策を求めます。逆に、政府こそが全ての解決策だと信じるのが民主党です。
今回のコロナウイルスに関しては「よくわからない」ことが多いです。そんなときには、「大きな政府」に解決を求めるモデルには限界があるのではないか、そのことによる結果を私たちは今、目にしているようです。
トレードオフという言葉がありますが、全てのことは行うと失うものがあります。社会にとって、市民にとって、本当に重要なこととな何なのでしょうか。このことは自分たちでだけでなく、次の世代のためにもしっかりと私たちそれぞれが考えていくべきではないでしょうか。
クリック・アンド・コレクト型のビジネスが急成長
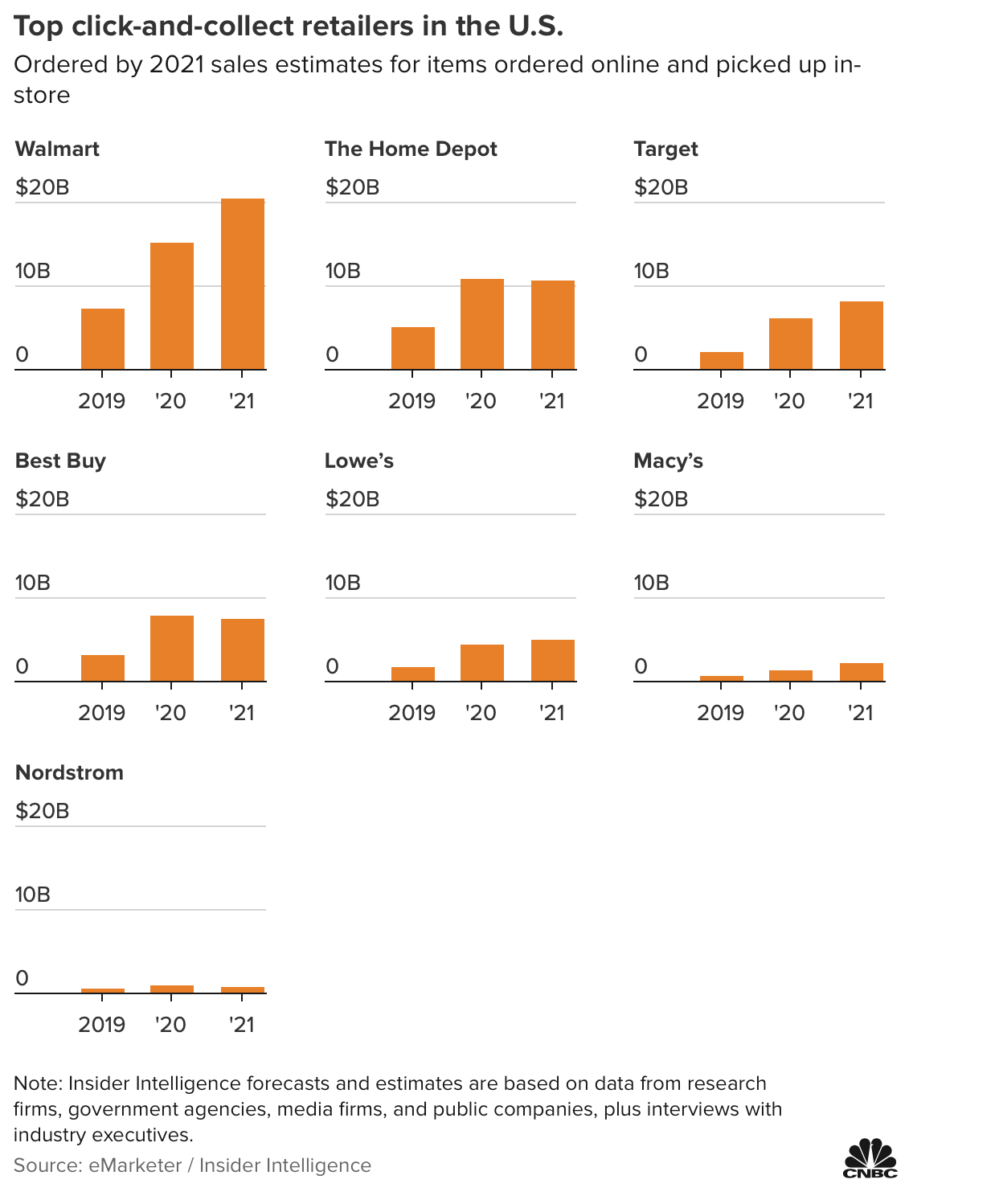
オンラインで注文し、店に行ってピックアップするといったタイプのサービス、そしてそれを好む顧客が増えているというのが最近のトレンドのようです。昨今のコロナによる影響下においては当たり前とも言えますが。。。

もちろん、どの小売でも同じトレンドがあるわけではありません。このトレンドを上手く利用しているのは、ウォルマート、ターゲットといった企業です。
このマーケットは来年2023年までには120ビリオンドル(約14兆円)規模に成長するとのことですが、こういった変化にソフトウェアとデータを使って素早く対応できるかどうかで大きな差がつきそうですね。
「学校からはじまるデータサイエンスの民主化」セミナー

3月18日(金)に「学校からはじまるデータサイエンスの民主化」セミナーを開催することが決まりました!
現在日本でも多くの学校でデータサイエンス教育を始めようと計画されていますが、何を学ぶべきなのか、どのようにカリキュラムを組めばよいか、教科書はどうするか、どういったサポート体制が必要か、レベル感は、文系と理系の違いは、などといった疑問を抱えていませんか。
そこでこの度、すでに大学でExploratoryを使って文系理系問わず幅広くデータサイエンスの教育を始められている先生方をお招きし、自らの経験をもとに現場での取り組みや課題などといったお話をしていただけることになりました。
これからデータサイエンス教育プログラムを作っていこうとされている方、また、すでに始められている方にとっても、他の学校の現場での経験から多くのヒントが得られるのではないかと思っております。
もちろん、大学関係者だけではなくデータサイエンス教育に関して興味のある方は誰でもご自由にご参加下さい。学生の方も大歓迎です。こちらのセミナーは無料となっております。
お時間の都合のつく方は、ぜひ参加をご検討下さい!
データサイエンス・ブートキャンプ・トレーニング #25

次回の「データサイエンス・ブートキャンプ」は2月となります。
データリテラシーを高めたい、またはデータサイエンス、統計の手法、データ分析を1から体系的に学び、ビジネスの現場で使える実践的なスキルをつけたいという方は、ぜひこの機会に参加をご検討ください!
日時: 2022/2/15(火), 16(水), 17(木)
講師:西田勘一郎
アンケートデータ分析トレーニング

アンケートデータを使って顧客をより深く、そして多面的に理解することは、ビジネスや提供するサービスを改善していくために必要不可欠です。
そのために必要な、データの加工、可視化、そして分析に関する手法をまとめて一気に学んでいただくためのトレーニングをこの3月に開催予定です。
アンケートは行っているが、その回答データをビジネスに活かしきれていないというお悩みをお持ちの方はぜひご参加を検討してみて下さい!
日時: 2022/3/11(土)
講師:西田勘一郎、村里郁哉、白戸敬登
今週は以上です!
それでは、良い週末をお過ごし下さい!
西田, Exploratory/CEO
KanAugust
