

Exploratory Newsletter Vol. 68
Exploratory Newsletter Vol. 68

こんにちは、Exploratoryの西田です。
今週の木曜日にマーケティング・アナリティクスシリーズ第2弾として、オンライン広告に関わる重要指標を紹介しました。そちらの動画をこちらに上げておりますので興味のある方はぜひ御覧ください!
それでは、今週のWeekly Update、さっそくいってみましょう!
最近の興味深い英文の記事
SaaS企業の成長エンジンは新規顧客の獲得とネット・レベニュー・リテンション
5 Interesting Learnings from Freshworks at $400,000,000 in ARR - Link
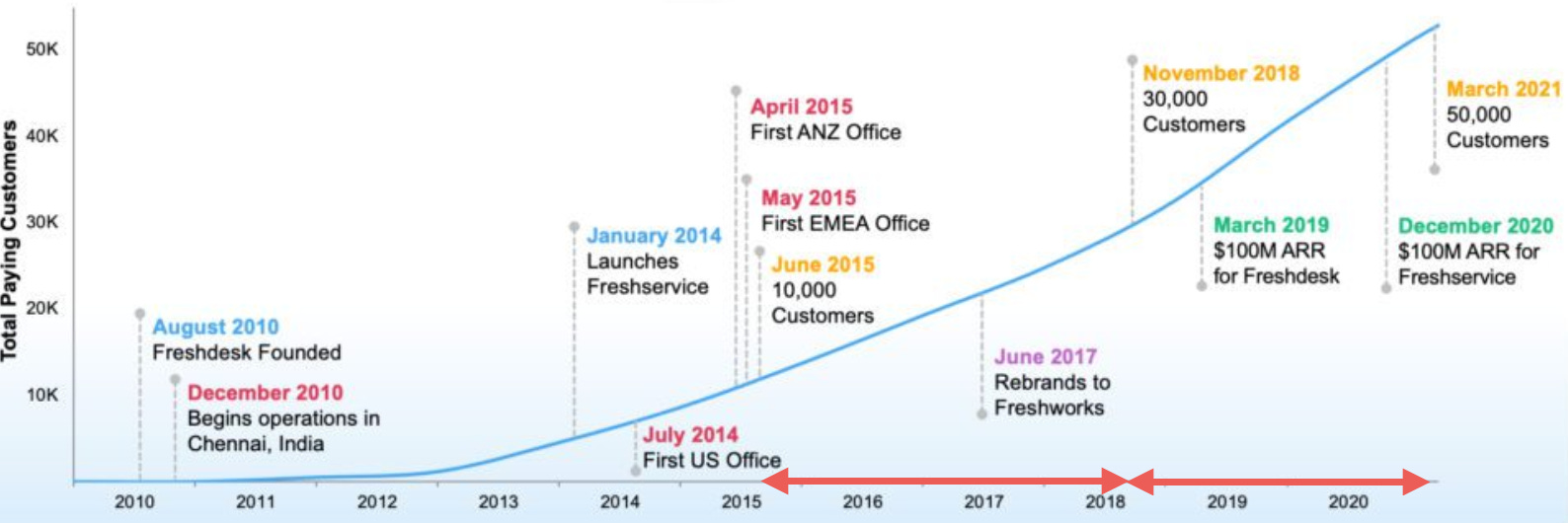
Googleやセコイアキャピタルから投資をうけ、先日上場を申請したカスタマー・サポート・プラットフォームを提供するFreshworksに関して注目すべき5つのこと、という記事です。
その中でも注目したいのは、直近1年で20%の顧客を増やすだけでなく、ARR(年間定期収益)を49%も増やしています。背景にあるのは118%という高いネット・レベニュー・リテンション率で、SaaSの成長には新規顧客の獲得と、ネット・レベニュー・リテンションであることがよく分かります。
SaaS / サブスクリプションビジネスの指標に関しては、こちらの「SaaSアナリティクス」ページの方にまとまっていますので、興味のある方はぜひご参照下さい。
60%の新規顧客は無料のチャネルより獲得
5 Interesting Learnings from HubSpot at $1 Billion in ARR - Link

毎年1ビリオン(約1000億円)を超える収益のあるマーケティング・オートメーション・サービスを提供するHubspotから学んだ5つのことという記事がありました。
その中で特に注目したいのが、60%の顧客が無料のチャネルから入ってくるという部分です。広告など、お金をかけるチャネル以外という意味です。
さらにその中でも圧倒的に多いのが、口コミ(Word of mouth)です。
これはだれもが理想とするところですが、やろうと思っても簡単にできるものではありません。プロダクト自身が、思わず他の人に伝えたくなるような価値をしっかりと提供できていたり、または成功体験を簡単に経験することができるようにプロダクトがデザインされている必要があるので、思いつきでできるものではありませんが、長期的な効果を考えるのであれば、しっかりとこの辺りは考慮して取り組んでいく必要がありますね。
ジョージ・ボックス:科学的手法を使って学ぶためには統計こそが重用である
Statistics as a Catalyst to Learning by Scientific Method Part II-Discussion - Link
現在、コロナに関連する様々な情報(ロックダウン、処方薬、ワクチン、マスク、など)が飛び交っており、どの情報が正しいのか、何を信用すればよいのか、といった判断をするのが難しかったりすると思います。
こういうときに、アメリカでは「クリティカル・シンキング」をしなくてはいけないとみんな言うのですが、いざとなるとどのように行えばよいのかはっきりせず、多くの人はそのまま自分の気に入ってるメディアの言うことをそのまま鵜呑みにしている状況です。
そこで、私たちの方でもこの「クリティカル・シンキング」というものを科学的手法に従うかたちで体系立ててしっかりと教育していくことができないかということで、そのトレーニングを現在開発中です。
キーとなるのはやはり科学的手法なのですが、そのコンセプトをこの「Weekly Update」で少しづつ紹介していきたいと思います。まずは、ジョージ・ボックスによる「学ぶプロセスとは演繹法と帰納法の繰り返しだ」というものです。
彼によると、私たちはこの2つのタイプの考え方をいつも交互に繰り返し行っています。
以下、引用。
まずは、何らかのデータまたは事実から始めますが、そこから帰納的にわかったことをもとに「モデル」を作ります。ここで言うモデルとは、仮説だったり推測だったり、考えだったりと言ったものだと思って下さい。
そして、次にこのモデルを演繹法を使って論理的に正しいのかどうかを見極めます。
というのも、もしこのモデルが正しければどんなことが起きるはずなのか、そして起こるだろうことと実際に起きたことを比べるためにはどういったデータが必要なのかを考えるのです。
そしてその違い、つまり理論的に起きるだろうことと実際に起きたこととの違いから「モデル」を棄却したり修正したりするのです。
ここで言う必要なデータとは、図書館に行って調べてきたり、あるプロセスを観察したり、実験をしたりといったものです。
こうして話すとややこしそうですが、例を使って考えてみましょう。
モデル:今日はいつもどおりの日だ。
演繹的思考:私の車は自分の駐車スペースにあるだろう。
データ:いや、車がありません!
帰納的思考:誰かが持ち去ったに違いない。
モデル:私の車は盗まれた。
演繹的思考:私の車は駐車場にはないだろう。
データ:いや、あそこに止まってます!
帰納的思考:誰かが盗んで、あそこに戻したんだろう。
モデル:盗人がとって、あそこに戻した。
演繹的思考:自分の車は壊されてるだろう。
データ:いや、まったく壊されてないし、ロックもかかってません!
帰納的思考:誰かキーを持ってる人がとったんだろう。
モデル:私の妻が車を使った。
演繹的思考:おそらく彼女はメモを残してるんじゃないか。
データ:はい、そのとおり!
引用、終わり。
このように私たちは、気づいているかいないかは別にして、普段から事実(データ)、帰納的思考、仮説(モデル)、演繹的思考、そしてまた事実(データ)というのを繰り返しながら「真実」に迫っていこうとしているのですね。
これがジョージ・ボックスの言う、「反復学習プロセス」というものです。
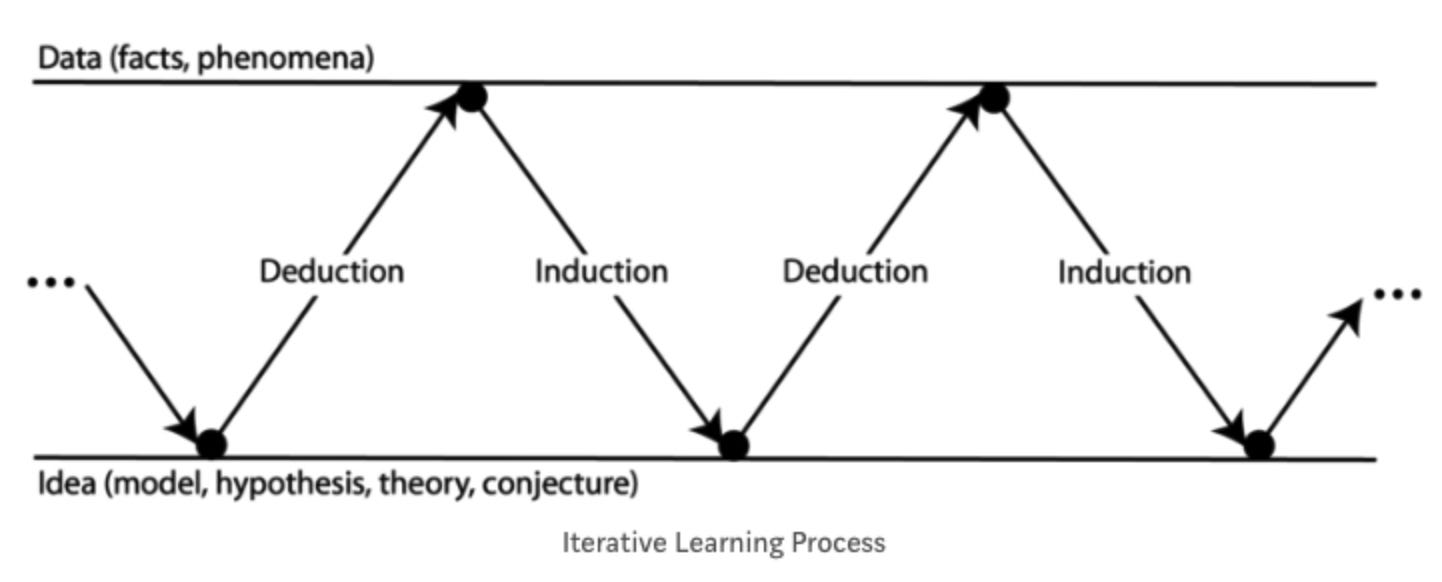
クリティカル・シンキングを考えるとき、私たち人間がどのように思考しているのか、このプロセスの整理が重用です。そして、このプロセスにはデータ、仮説、モデルと言ったものが出てきますが、これこそが統計の知識や考え方を知ることなしにクリティカル・シンキングを身につけることはできないと、私が強く思う所以でもあります。
今週の名言
統計学とは、科学的探求のためのものであり、それをいかにうまくやるかというものである。しかし、多くの統計学者は統計学とは数学の一部だと信じてしまっている。
Exploratory データ・アカデミー
データサイエンス・ブートキャンプ・トレーニング #24

毎回好評をいただいているデータサイエンス・ブートキャンプですが、次回は11月の開催となります。
データリテラシーを高めたい、またはデータサイエンス、統計の手法、データ分析を1から体系的に学び、ビジネスの現場で使える実践的なスキルをつけたいという方は、ぜひこの機会に参加をご検討ください!
日時: 2021/11/9(火), 10(水), 11(木)
講師:西田勘一郎
データサイエンス勉強会 #21

11月12日(金)に「Exploratoryデータサイエンス勉強会 #21」を開催します!
今回も4人のExploratoryユーザーの方たちに、具体的なデータに関する取り組みやデータ分析のリアルの話を共有していただく予定です!
私の方からもいつものようにExploratoryの時期リリースであるv6.8のアップデートをさせていただきます。
お時間の都合のつく方は、以下の詳細ページより参加をお申し込みの上ご参加下さい!
なお今回もオンラインでの開催となります。
今週は以上です。
それでは、素晴らしい週末を!
西田, Exploratory/CEO
KanAugust
