

Exploratory Newsletter Vol. 107
Exploratory Newsletter Vol. 107
パワポのスライドと箇条書きが人間を駄目にする、AIのバイアス、AIのオープン化、など

私達の思考が馬鹿げているせいで英語は醜く不正確なものになってしまった。しかし、この英語のだらしない性質そのものが、私達が馬鹿げた思考をする助けとなっているのだ。
- ジョージ・オーウェル (Politics and the English Language), 1946
こんにちは、西田です!
ちょっと前にこのようなチャートを見かけたのですが、それ以来このことが私の頭から離れません。

様々なジャンルにおいて時代とともに私達の体験の仕方の移り変わりを表したものですが、ゆっくりと時間をかけた体験から、より早く簡単な体験へ、そして最近では短時間の間にいかに刺激を得ることができるかを重視した体験に変わってきたというものです。
わかりやすい例としては、動画であれば昔は映画やテレビでそれなりの時間をかけ、見たくないものも含め全てのパッケージとして見ていたものが、自分の好きなものを選択して録画し、好きな部分に早送りして見ることができるようになり、さらには最近ではYoutube ShortやTiktokのような数秒で興奮できるものを見るようになってきたというものです。
短期的な刺激や快楽、そして便利さを求めいつも「モダン」な時代に生きる我々人類は、いよいよここまで来てしまったわけですが、そのかわりに失いつつあるのが思考ではないのかと思わずにいられません。
次から次へと洪水のように降ってくる情報の波にただ流され、立ち止まって考える時間、くだらないことも含めあーだこーだと思考を巡らせる時間がなくなることで、私達は自分というものを見失いつつあるのではないでしょうか。そしてこうした私達の世代は情報を流す側にとってよりコントロールしやすい世代となってしまったのではないでしょうか。
それに関連して、ビジネスなどの報告書やコミュニケーション手段としてよく使われるパワポのスライドと箇条書きリストが私達人間から思考力を奪い取っているのではないかとする、今から20年ほど前に書かれたエッセイを紹介する記事を最近書きました。詳しくは今週の記事として以下に紹介していますのでぜひ読んでいただければと思います。
ところで話は変わりますが、今月の29日、金曜日の夕方に「Exploratoryユーザー会」を開催します。今回より、これまでどおりExploratoryユーザーの方にビジネスの現場でどのようにデータを活用されているのか発表していただくものですが、今回よりライトニングトーク(5分での短い発表)や学生の方たちによる発表も加わり、より強力なラインナップとなっています。お時間の都合のつく方はぜひお気軽にご参加下さい。
それでは、今週もいくつか興味深いデータ関連記事を紹介します!
最近の興味深いデータ関連記事
パワポのスライドと箇条書きが人間を駄目にする
今から20年前の2003年、データの可視化やインフォメーションデザインの先駆者として有名なイエール大学の教授エドワード・タフティが「パワーポイントの認知スタイル」というエッセイを発表しました。
彼はこのエッセイの中で、パワーポイントのようなスライド形式はプレゼンテーション自体の質を低下させ、余計な誤解や混乱を招き、さらに言葉の使い方、論理的な説明、そして統計的な分析といったものが犠牲になるため、スライドをつくる人の思考回路にダメージを与えると主張します。
こうした主張に賛同する人は現在でも多くいて、その典型的な例がアマゾンです。アマゾンではミーティングの前に文章形式の資料が配られ、ミーティングの最初の5分はそれぞれがこの配られたレポートを黙って読むことから始まるという話は多くの方も聞いたことがあるのではないでしょうか。(リンク)
実は、アマゾンのジェフ・ベゾス(創業者、元CEO)や初期チームのメンバーは、実際このエッセイを読んだ後に社内ミーティングでのパワーポイントのようなスライドの使用を禁止し、その後文章形式のレポートに変えたとのことです。
今回は、何がパワーポイントのようなスライドの問題なのか、どのようにそういった問題を克服すればよいのか、元のエッセイを要訳という形でまとめてみました。
ChatGPTを人事採用に使うと起きるバイアス
OpenAI’s GPT is a recruiters dream tool. Tests show there’s racial bias - Link
人事採用の際に送られてくる大量の履歴書を1つ1つ読む代わりに、生成AIが事前にスクリーニングして、自社に適している人材の履歴書だけを選び、さらにそれらの要約を送ってくれると嬉しいですよね。
ただ生成AIと言っても中の仕組みは基本的にこれまでの機械学習モデルと変わりません。つまりインプットとなる過去データがあって、その中にあるパターンをモデルとし、答えのない新しいデータを入れるとモデルがその答えを予測してくれるというものです。
ということは、これまでの機械学習で問題になったことが結局は生成AIでも問題となります。つまり過去データに自ずと含まれる偏りによってバイアスが作られてしまうということです。
これは昔、2018年頃にアマゾン社で問題になったことです。過去の採用人材に男性が多かったため、そうした過去データを元に作られたモデルは女性の履歴書は自社に適していないと判断してしまい、そのため女性の採用が進まなくなってしまったというものです。
現在多くの企業ではOpenAIのChatGPTを使った人事採用を実験中ですが、実際こうしたバイアスが人種差別という形で出てきているとのことです。
これは難しい問題で、バイアスを直すために下手に手をいれると今度はGoogleのAIのようにWokeなAIとなってしまうこともあります。
リベラルWokeなAIによって化けの皮を剥がしたGoogleと民主主義の危機 - Link
生成AIにしろ機械学習にしろこうしたインプットデータとなる過去のデータによるバイアスがシステム的に入り込んでしまうという限界をしっかりと理解したうえで使っていくことが求められます。やみくもに、まるで黄金の武器を持ったかのように全てをAIに任せてしまうのは、まだまだ先の話です。この当たりの限界を認識することなしに知らず知らずのうちに問題が起きてしまい、後から気づいたときには取り返しのつかないことになってることもあるのです。
Amazon scraps secret AI recruiting tool that showed bias against women - Link
これは機械学習を使う限り起きる問題という意味で古い問題ですが、事情をよく理解せずに使う企業にとっては新しい問題として出現することになるでしょう。
インドではAIモデルに差別とバイアスがないかのチェックが義務付けられる
India reverses AI stance, requires government approval for model launches - Link
インドでは全てのAIモデルは政府による承認が必要で、そのためにはバイアスや差別がないことが必須となるとのこと。上記でも話しましたが、バイアスのないAIモデルなんてものは存在しません。この世の中はバイアスもあれば、味方によっては差別となることもたくさんあります。そんな世の中にあるデータを元にAIモデルは作られるわけです。無理やりバイアスや差別をAIモデルから無くそうとすると、逆におかしなバイアスを抱えてしまうことになり、それはもうカオスになるでしょう。
リベラルWokeなAIによって化けの皮を剥がしたGoogleと民主主義の危機 - Link
イーロン・マスクがGrokをオープンソースにすると発表
Elon Says Grok Will Be Open Source - Link
先週イーロン・マスクは彼のAIスタートアップ xAIが作るChatGPTへの対抗となるGrokをオープンソースすると発表しました。(リンク)
ちなみにその直前にイーロン・マスクはChatGPT開発元のOpenAIを訴えています。元々非営利企業としてオープンな環境でAIを開発するという約束を破り、今やクローズドな環境で営利のためにAIを開発するための企業になってしまったというのが理由です。このあたりの背景は過去のニュースレターでも述べたので詳細はそちらを参照下さい。
いずれにせよ、このGrokをオープンソースにすることで世界中の開発者がそのコードに自由にアクセスし実際に自分たちで何かを開発したりすることができるようになります。
またさらに重要な点として、GrokというLLM(Large Language Model)がどのように手を加えられているのかが透明化されるということです。こちらの記事でも解説したように、ChatGPTにしてもGoogleのAI(Gemini)にしても極端なリベラル、そして党派的なバイアスが人工的に作られていますし、さらに政府から圧力の元、ソーシャルメディア各社は一部の情報「検閲」しています。こうした人工的に作られたバイアスや検閲のルールを誰の目にも明らかにすることは、民主主義を標榜する社会においては非常に重要なことであると思います。
ちなみに、Meta(Facebook)もLLAMAという彼らのLLMをオープンソース化しています。
AIのオープンソース、クローズドというのは現在も様々な場所で議論されていますが、AIはますます私達が情報へアクセスするための手段となりつつあるだけに、これからのAIのオープン化の動きは誰もが注目すべき重要な問題だと思います。
今週のデータ
以下は世界中の人達に対して行った、AIが自分たちの仕事にポジティブ、またはネガティブな影響を与えたかに関するアンケート調査です。(リンク)インドやインドネシアなどは半数以上の人が生産性が上がったとポジティブな反応(紫)を持っているのに対し、アメリカでは上がった(紫)と思ってる人の割合が低いという結果が出ています。
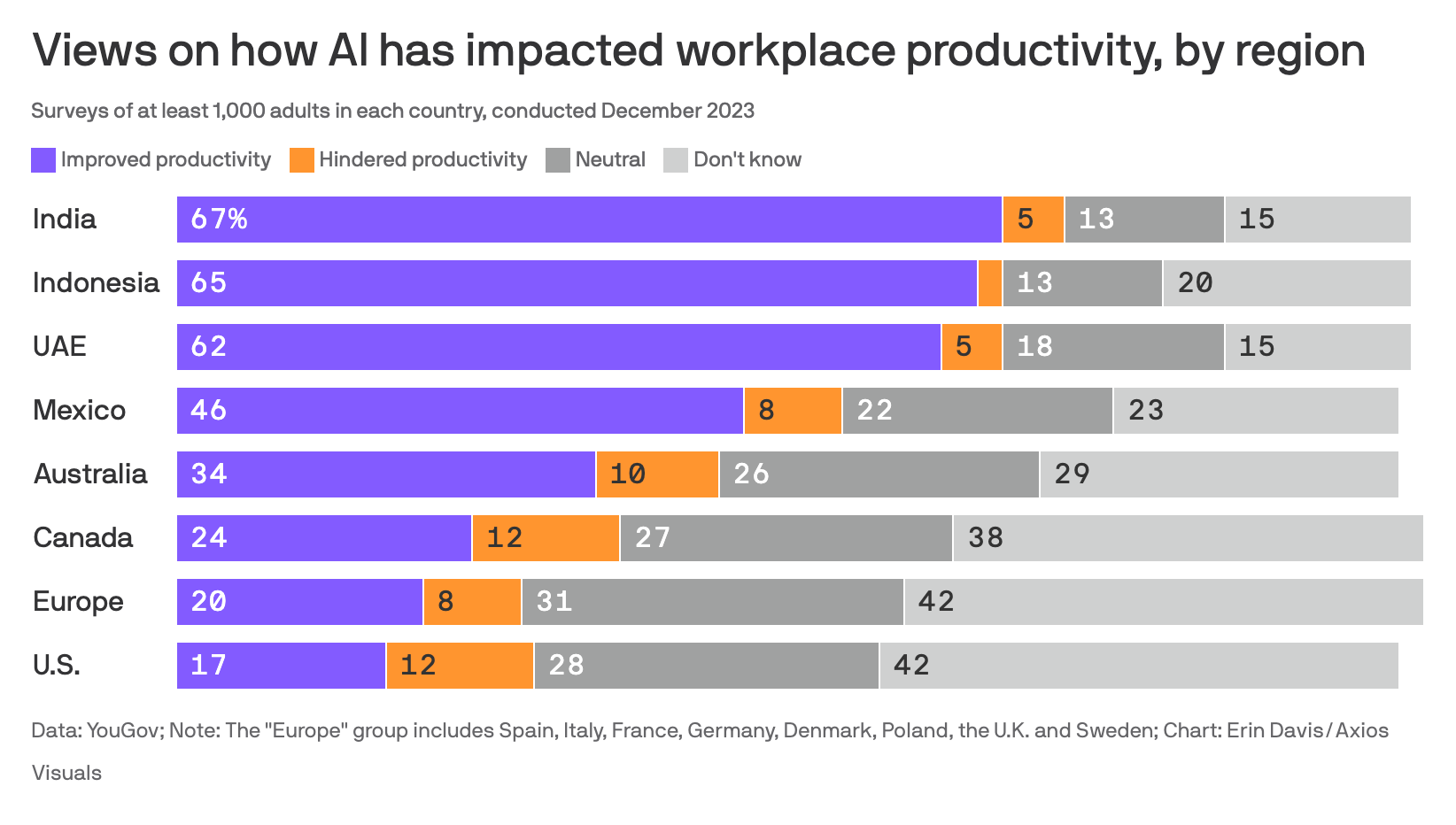
ただ、アメリカやヨーロッパの場合は、どちらでもない、よくわからないという人の割合も高いことから、実はあまり使っていない、もしくは実は使っていても使っているという感覚がないということなのかもしれません。
また、非英語圏の人たちのほうが例えば、自動翻訳と言ったわかりやすく実用性のあるAIに対して恩恵を受けたと感じることができるかもしれず、そのことが結果に反映されているのかもしれません。
Exploratoryのセミナー
#132 - Exploratoryでノートを作る際に知っておくと便利な10の機能
Exploratoryではインタラクティブなチャートと文章を使って、データ分析から得られたインサイト(知見)を他の人達に効果的に伝えていくために、簡単に「ノート」を作ることができます。
先週は、ノートを作る際に知っておくと便利な機能についてセミナー形式で紹介しました。
2つの改行タイプ
チャートのサイズ調整
チャート - コメント、編集
チャートとデータの更新
目次の表示と設定
見出しへのリンク(アンカー)
パラメーターを使う
Webページの挿入
LaTeXフォーマットを使った数式
Rスクリプトを使った機能拡張
データサイエンス・ブートキャンプ・トレーニング #35

毎回人気のデータサイエンス・ブートキャンプですが、次回開催は6月となっております。
次回も東京でのクラスルームでの対面授業形式での開催となります。
ビジネスのデータ分析だけでなく、日常生活やキャリア構築にも役立つデータリテラシー、そして「よりよい意思決定」をしていくために必要になるデータをもとにした「科学的思考」もいっしょに身につけていただけるトレーニングとなっています。
データサイエンス、統計の手法、データ分析を1から体系的に学ぶことで、ビジネスの現場で使える実践的なスキルを身につけたいという方は、ぜひこの機会に参加をご検討ください!
日時: 2024年6月18日(火), 19日(水), 20日(木)
場所:東京八重洲(対面形式)
Exploratoryユーザー会 #31

今月の3月29日(金)に「Exploratory ユーザー会 #31」を開催します。
今回より、ユーザー様主体のユーザー会として運営していくこととなりますが、内容の方はこれまでと基本的に同じく、ユーザー様が普段行われているデータ分析やデータ活用事例を発表していただく予定です。
今回から新たにライトニング・トーク(LT / Lighting Talk)や学生の方の発表枠も追加され、より内容が盛りだくさんとなっております。
Exploratoryユーザーの方はもちろん、データやExploratoryに興味のある方もぜひお気軽に遊びに来て下さい!
今回のニュースレターは以上となります。
それでは、素晴らしい残りの週末をお送りください!
西田, Exploratory/CEO
KanAugust
