

Exploratory Newsletter Vol. 105
Exploratory Newsletter Vol. 105
ノーススター指標、GoogleのWokeなAI、AIチャットボットの法的責任、日本の失業率、など

こんにちは、西田です!
最近私の住むアメリカでは日本がリセッション入りしたとのニュースが一時賑わいました(リンク)。しかしその後、日経平均株価は過去最高を記録し、リセッションという暗いニュースを一気に吹き飛ばし、世界中が日本に羨望の目を向ける状況となりました。(もちろんこの後株価がどうなるかというのはわかりませんが。)
ところで、もう一つ世界が日本に羨望の眼差しを向けるデータがあります。それは日本の失業率です。実は日本の失業率は、他の海外の国などと比べるとかなり低いんです。以下はOECD加盟国の失業率の推移を表したものですが、一番右下が日本です。
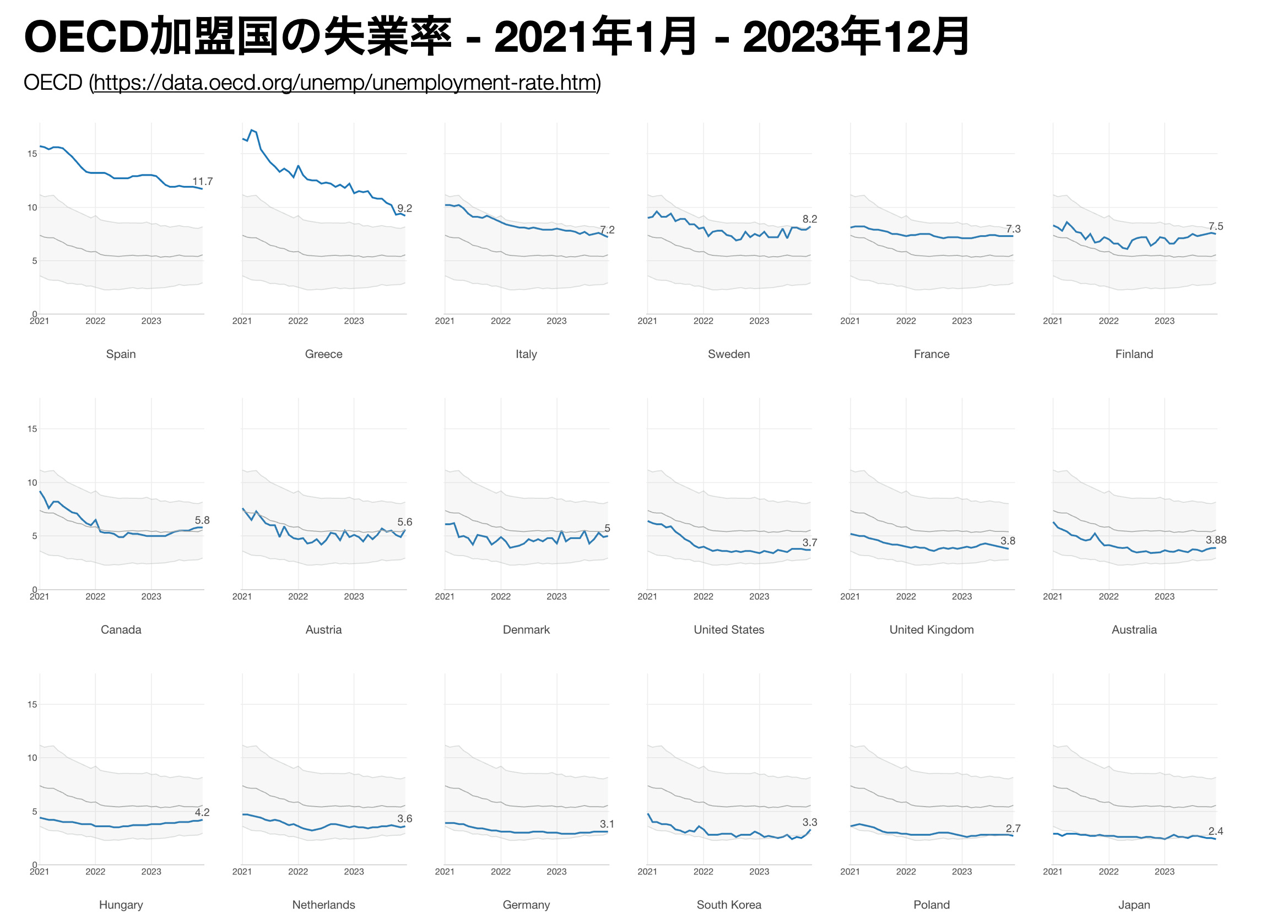
日本の失業率が低いという話をすると必ず、いや日本の給料は伸びてない!といってくる人達がいるのですが、それはさておき、仕事があるかないかというのは自分への自信や人間の尊厳にも関わってくる問題だけに、この「世界に比べると失業率が異常に低い」という事実はもっとポジティブに捉えらてもいいのではないかと思います。
それでは、以下データ関連の記事の紹介です。
最近の興味深いデータ関連記事
ノーススター(北極星)指標をモニターしてるのにビジネスが成長しないのはなぜか?

よくスタートアップやSaaSの世界などでノーススター(北極星)指標が注目されます。自分たちのビジネスを成長させるために組織の全員が一丸となって追うべき1つの指標というものです。
例えば、アクティビティの指標であるDAU(Daily Activity Users)やMAU(Monthly Active Users)であったり、またはエンゲージメントを測るためのDAU/MAU、またはそれこそ売上やMRRであったりするかもしれません。
データや数値を元にビジネスを成長させようということで、こうした「ノーススター」指標を決め、ダッシュボードなどで毎週、毎月モニターし始めます。
ところが、ここから誰もが話したくないことが起き始めます。
たいていの組織や企業の中の人達はこの指標をだんだん見なくなる、または本気にしなくなります。
実際見ている人は経験あると思うのですが、こうした指標の数値は良くなったり悪くなったり、つまり上がったり下がったりするものです。ずっと上がり続けたり、下がり続けたり、といったことはあまりありません。
この数値が良かったときはみんなウキウキし、褒め合ったり、成果を誇示したりし、逆に悪くなったときはみんなの(特に上司の)機嫌が悪くなり、どなったり、文句を言ったり、他の誰かを責めたり、といったことになります。
そうこうしてるうちにみんな指標に振り回されることに疲れてきて、半年も経てば見るのも嫌になり、終いには誰もこのノーススター指標を見なくなります。
せっかく「データドリブンになるぞー!」といって勢いよく始めたプロジェクトは、こうして何かしっくりこないうちに終わっていきます。
もちろん現実はここまで極端ではないかもしれませんが、これに似たような経験のある方も多いのではないでしょうか?
ちなみに、私は直接こういう経験をしたことが過去に何度かありますし、お客様などからこういった話を寄せられることも多いです。
ではなぜ、こういったことが起こるのでしょうか?
そもそもデータを使って、または指標を使ってビジネスを改善するなんてことは無理なんでしょうか?
いえ、そんなことはありません。上のような状況になるのは実は当たり前で、というのもそれはノーススター指標の使い方を間違えているからなのです。
そもそもノーススター指標とは、みなさんのビジネスにおける様々な活動や施策の結果が最終的に数値として表されるものです。つまり「結果の指標」です。
結果なので、この指標が悪かったというとき、すでにゲームは終了しているのです。もちろん、次の月、四半期に向けて何か対策しようということになりますが、相変わらずこの結果の指標を見ているだけでは、何も変わりません。というのも、みなさんがいったい何をすればよいのか、何を軌道修正すればよいのか、この指標は何も教えてくれないからです。
ノーススター指標という結果の指標を宗教的に追い続けてしまい、その結果に影響を及ぼすためのどういったアクションを起こせばよいのか学ぶための指標を見ることができていないのが問題なのです。
これでは、「データを使ってビジネスをドライブ」するという意味でのデータドリブンではなく、「データにドライブされる」という意味でのデータドリブンになってしまいます。
そこで、ノーススター指標をモニターすることの問題点と、ビジネスを改善するために追うべきインプット指標の選び方の話を、以下の記事を元にこちらにまとめました。
Don't Let Your North Star Metric Deceive You - リンク
自分たちのチームや組織をもっとデータドリブンにしたいと思われている方は、ぜひ参考にしてみて下さい!
リベラルWokeなAIによって化けの皮を剥がしたGoogleと民主主義の危機

最近GoogleがChatGPTに対抗するサービスとしてGeminiをリリースしました。ところがこのGoogleのAIが出す答えが、「Woke(ウォーク)」と言われる極端なリベラル思想のバイアスにまみれてあまりにもひどいので、あらゆる方面から叩かれていました。
これまでもGoogleの検索結果には「Woke」なバイアスがかかっているというのはよく言われていました。
Google検索の左寄りバイアス - リンク
ところが、この度のGoogleのAI(Gemini)が生成するイメージやテキストの結果に見られるバイアスはひどいを通り越し、Googleの組織的なWokeなバイアスを世間にさらすこととなりました。
もちろん、GoogleのAIに対する信頼が揺らいだというのもGoogleにとっては問題ですが、それ以上に今回のようなWokeなバイアスを内包したAIの登場は、一部のテック企業によってAIが独占されることの弊害、そしてそのことによる民主主義の危機を示しています。
そのことについて、まずはいくつかのGoogleのAIによるバイアスの例を提示し、その後、このことが示す問題を解説してみたいと思います。
企業はAIチャットボットが生成する情報に法的責任を負うのか?
カナダの航空会社であるエア・カナダが提供するAIチャットボットが、お客に対してチケットを買った後に払い戻しができるという、会社のポリシーとは反する間違った情報を提供してしまったとのことです。
その後、そのお客との間で裁判沙汰になってしまったのですが、最終的にはエア・カナダが敗訴し、お客に対してチケットの払い戻しをし、さらに今回の件に関してお客が被った被害を弁償することになってしまったとのことです。間違った情報だったとしても、エア・カナダ側がお客に提供した情報なのであればエア・カナダは法的な責任から逃れられないとのことです。
カスタマーサポートなどで使われるチャットボットに、最近のChatGPTのようなAI(LLM)を組み込めば、より多くの質問に素早く、さらにより的確な情報を持って答えることができるというメリットがあります。しかし、ChatGPTやGoogleのGeminiがそうであるように、こうしたAIはいつも正確というわけではありません。この世界では「ハルシネーション」と呼ばれたりもしますが、平気で間違った情報を返すこともあります。
もちろん、今回の払い戻しのようにたとえ間違った情報を返したとしても、そのコストは(金額的には)たいしたことなく、それよりもAIチャットボットを使ったことによるコスト削減の方が圧倒的に大きいとも言えるので、そうした判断によってAIチャットボットを運用するというのも1つのやり方だとは思います。
重要なのは、こうしたベネフィットとリスクをしっかりと認識し、評価した上で、意思決定をする必要があるということです。そうしたリスクを減らすためには、AIに全てを任せるのではなく、ドメイン知識を持った人間がAIのアウトプット情報の正確さ、的確さを絶えず判断できる仕組みを持つことが企業側に求められます。
今週のデータ
TWD #16 - 世界に比べて異常に低い日本の若者の失業率
今回のニュースレターの冒頭でも触れましたが、世界の国々と比べると日本の失業率はすごく低いというのは、あまり知られてない事実です。
そして、さらに知られていないのは、日本の若者の失業率は世界と比べてさらに低いという事実です。

一般的にどの国でも若者の失業率は全体よりもはるかに高い傾向があります。しかし日本の場合、全体と若者の失業率はそんなに違いがなく、どちらも他国に比べるとかなり低い傾向にあります。
日本だけに注目し、連日メディアで報道される国内の様々なスキャンダルに滅入ってしまいますが、実は他国からすると羨ましがられるほど、現在、経済環境がうまくいっている国、それが日本です。(もちろん、この後どうなるかというのはわかりませんが。)
Exploratoryのセミナー
少し前になりますが、去年12月から今年1月にかけてあった国連総会の決議をランダムに10個選択し、 それらに対する投票パターンを元に類似度を計算し可視化してみたのが以下のチャートです。

アメリカが他の国に比べて大きく離れています。
実はこの傾向は最近始まったわけではありません。 以下はオバマ政権のときの全ての国連決議の投票データをもとにしたものです。

メディアを見ていると、ロシアや中国などが国際社会から孤立し、アメリカが国際社会の中心にいるような錯覚を受けますが、国連総会での投票パターンから見える世界は実はその逆だったりします。国連決議投票データはそういった意味で、私達に重要な視点を与えてくれる貴重なデータです。
こちらのセミナーでは、国連決議データの取得方法、投票パターンを元にした距離の計算方法、そしてMDSというアルゴリズムを使って2次元空間で上記のように可視化する方法を解説しています。
データサイエンス・ブートキャンプ・トレーニング #34

毎回人気のデータサイエンス・ブートキャンプですが、次回開催は今月3月となっております。
今回も東京でのクラスルームでの対面授業形式での開催となります。
ビジネスのデータ分析だけでなく、日常生活やキャリア構築にも役立つデータリテラシー、そして「よりよい意思決定」をしていくために必要になるデータをもとにした「科学的思考」もいっしょに身につけていただけるトレーニングとなっています。
データサイエンス、統計の手法、データ分析を1から体系的に学ぶことで、ビジネスの現場で使える実践的なスキルを身につけたいという方は、ぜひこの機会に参加をご検討ください!
日時: 2024年3月26日(火), 27日(水), 28日(木)
場所:東京八重洲(対面形式)
Exploratoryユーザー会 #31

3月29日(金)に「Exploratory ユーザー会 #31」を開催します。
今回より、ユーザー様主体のユーザー会として運営していくこととなりますが、内容の方はこれまでと基本的に同じく、ユーザー様が普段行われているデータ分析やデータ活用事例を発表していただく予定です。
今回から新たにライトニング・トーク(LT / Lighting Talk)や学生の方の発表枠も追加され、より内容が盛りだくさんとなっております。
Exploratoryユーザーの方はもちろん、データやExploratoryに興味のある方はぜひお気軽に遊びに来て下さい!
今回のニュースレターは以上となります。
それでは、素晴らしい週末をお送りください!
西田, Exploratory/CEO
KanAugust
